👆左为ResNet,右为ResNeXt cardinality=32
平行堆叠代替线性加深,不显著增加参数数量级增加准确率;同时平行分支的拓扑结构相同减少了超参数(设计成本)
👆split-transform-merge过程
👆三种等价的结构,第三种简洁,速度更快
传统为增加深度(层数)和宽度(特征维度),变成结合VGG的堆叠网络+Inception的 split-transform-merge 策略。增加准确率和可扩展性同时不改变或减小复杂度
提出cardinality,表示多分支的分支数量,more effective
👆左为ResNet,右为ResNeXt cardinality=32
平行堆叠代替线性加深,不显著增加参数数量级增加准确率;同时平行分支的拓扑结构相同减少了超参数(设计成本)
👆split-transform-merge过程
👆三种等价的结构,第三种简洁,速度更快
Dilated Conv
把传统卷积变成depth-wise卷积和1x1卷积
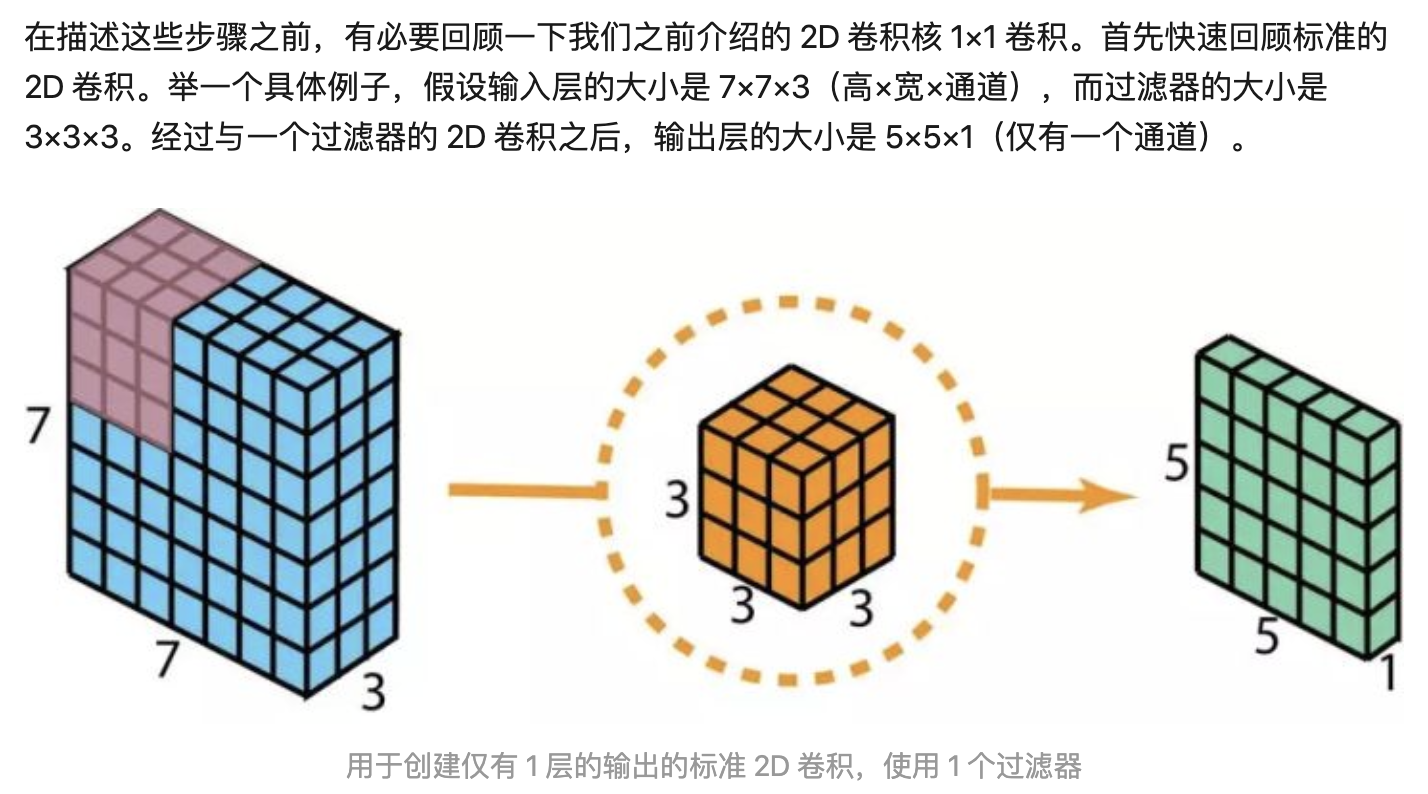
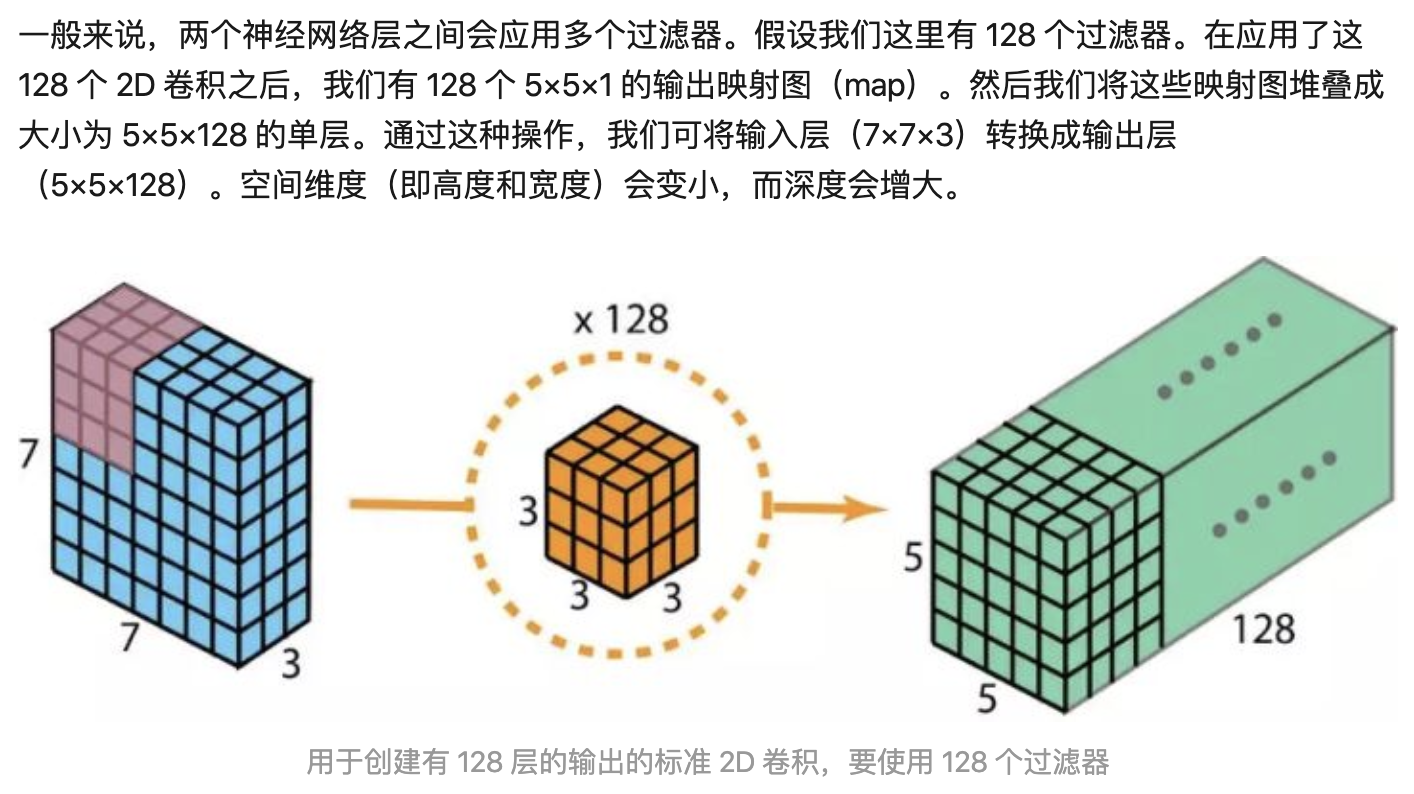
标准卷积(Dk卷积核大小,Df输出特征图尺寸,M输入通道,N输出通道)
深度可分离卷积:depth-wise卷积和1x1卷积
Depth卷积把输入特征图Dk x Dk x M成Df x Df x M层,然后1x1把M层变为N层输出
👆depth-wise conv不同特征图通道使用不同卷积核,M层特征图卷积还是M层(不相加)所以Dk x Dk x M x Df x Df(一个卷积核计算Dk x Dk次,构成输出特征图的一个点,所以一张输出特征图一共计算Dk x Dk x Df x Df次,一共M层)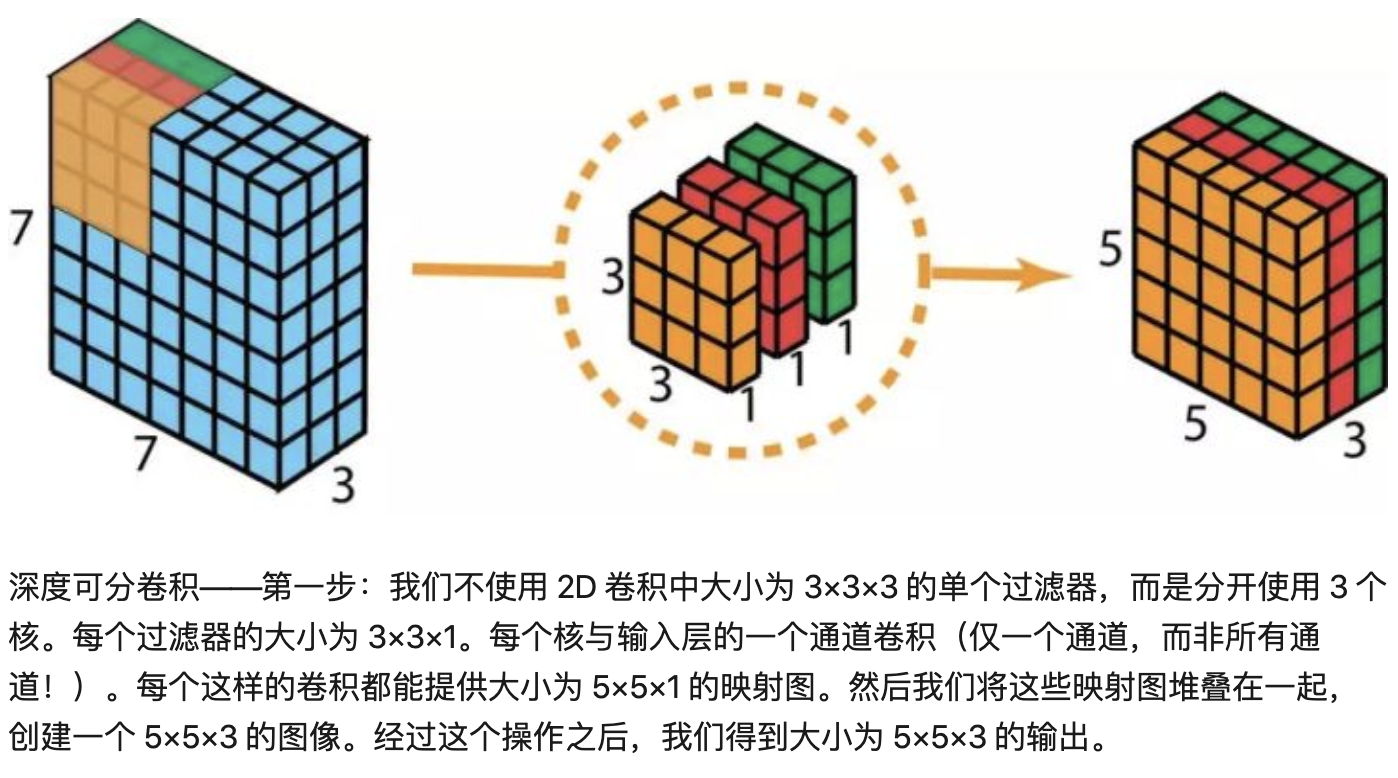
👆depth-wise解释
👆point-wise conv不同特征图使用同一个卷积核,但是1x1。把M通道卷积成N通道,所以M x N x Df x Df (一个卷积核计算M层相加,再计算N次构成N通道)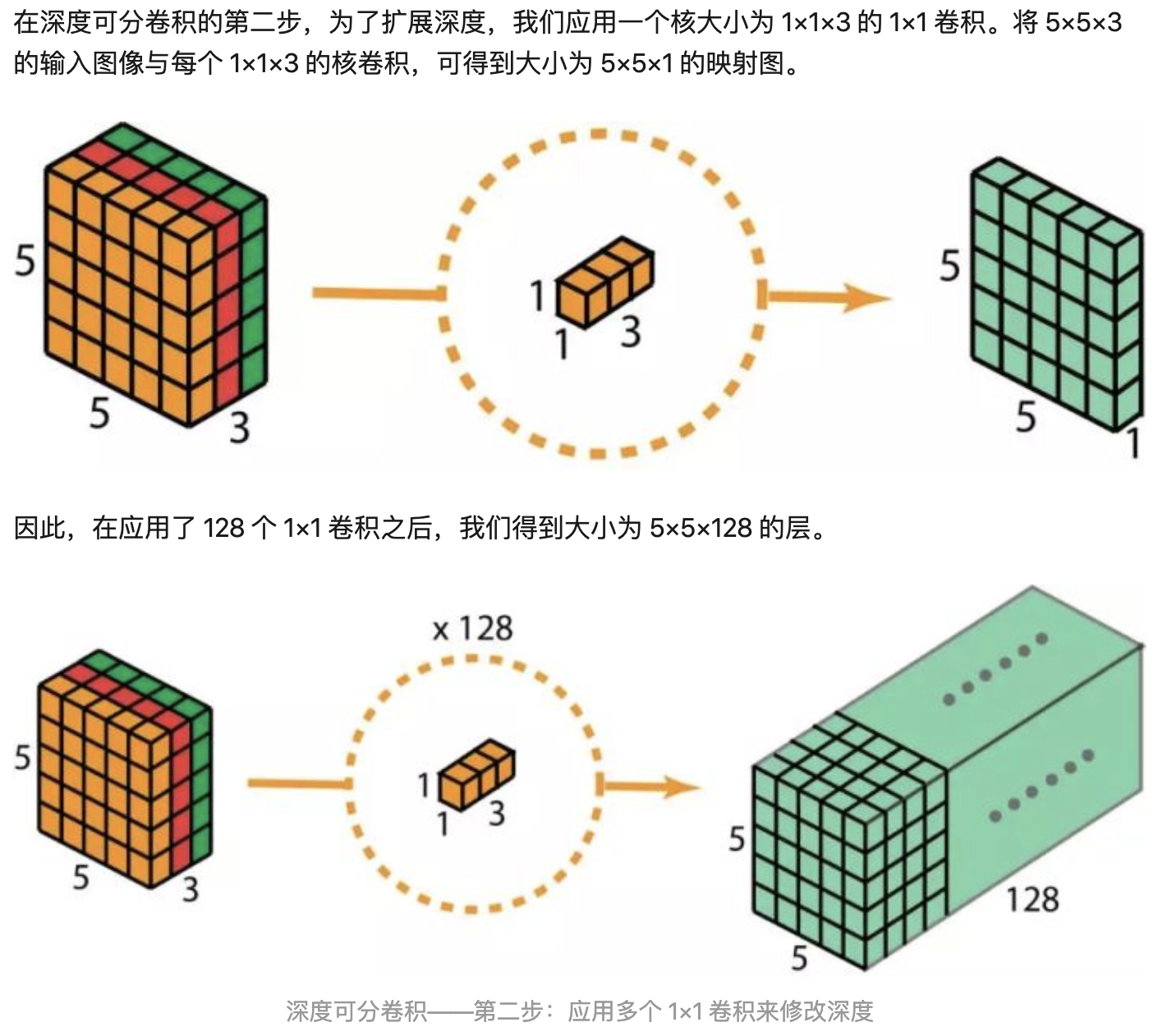
👆point-wise解释
参数量 H x W x C1 x C2
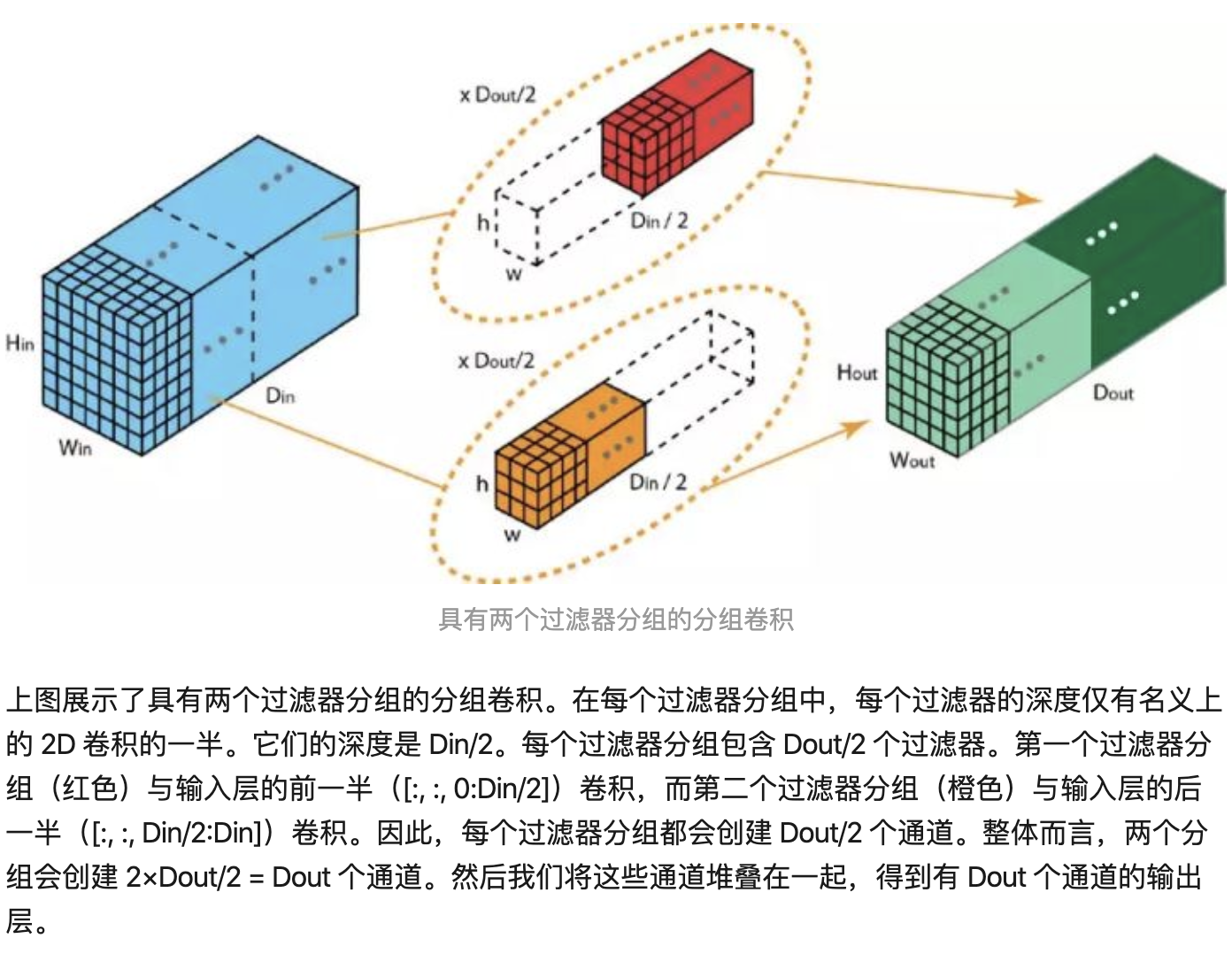
卷积核之间的关系是稀疏的。group conv减少卷积核之间的关联性, regularization,减少过拟合
Ref: A Tutorial on Filter Groups (Grouped Convolution) - A Shallow Blog about Deep Learning
增加inverted residual with linear bottleneck,首先升维,卷积,再降维。 特征提取在高维空间进行 。纺锤形,和resnet的hour-glass相反,所以inverted
在DW之前 增加PW卷积:上一层通道数少,则DW只能在低维空间提取特征,增加PW后,先升维,再提DW特征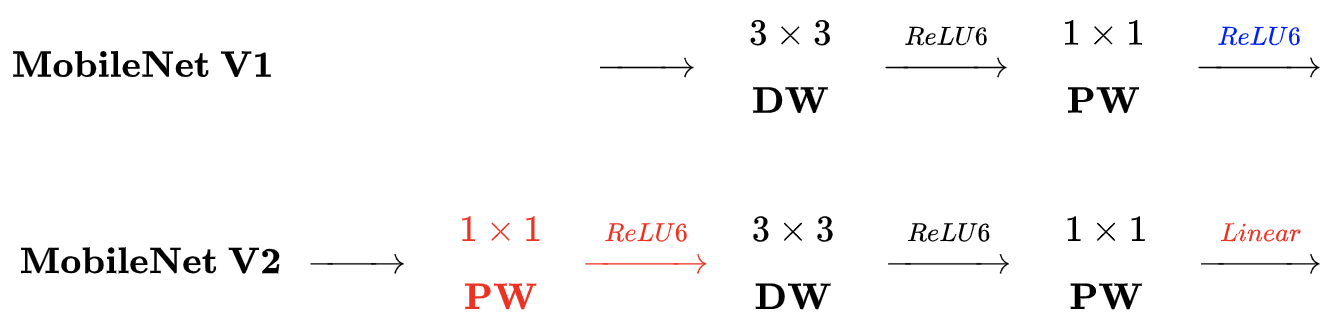
去掉了第二个PW的 激活函数 :只有在高维空间中,激活函数可以增加非线性;而在低维空间中,激活函数会破坏特征。因此采用线性
增加 shortcut 连接,输出与输入相加:同ResNet
组内point-wise卷积,增加shuffle操作通道之间信息沟通
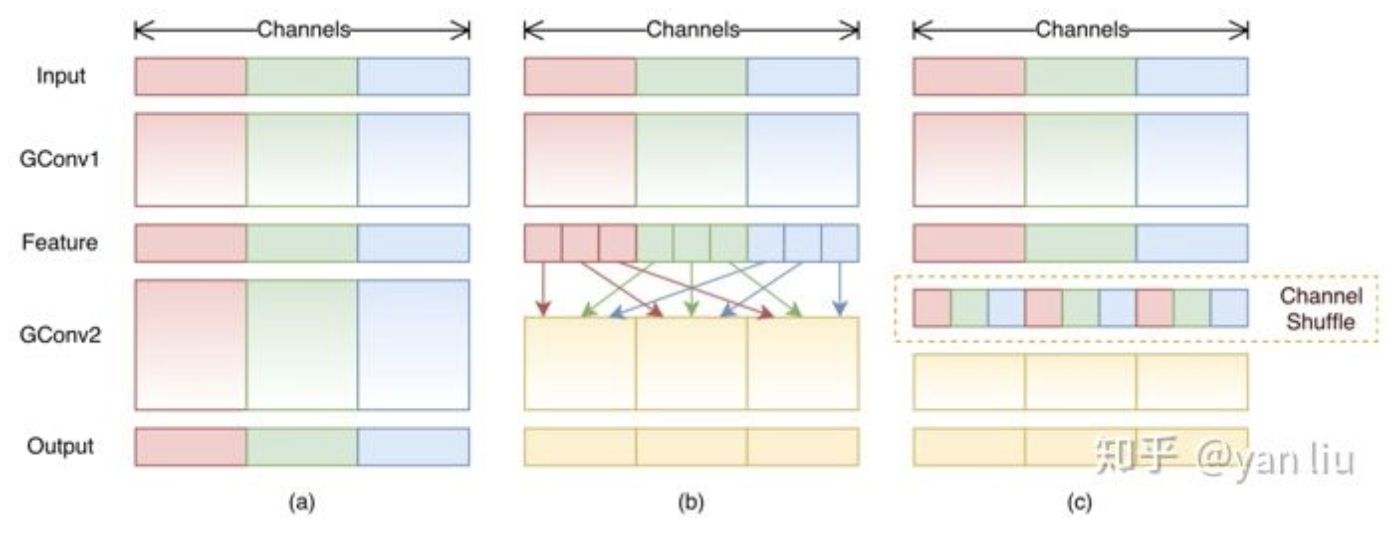
👆a:normal,b:分组卷积,c:channel shuffle
另一种理解👇
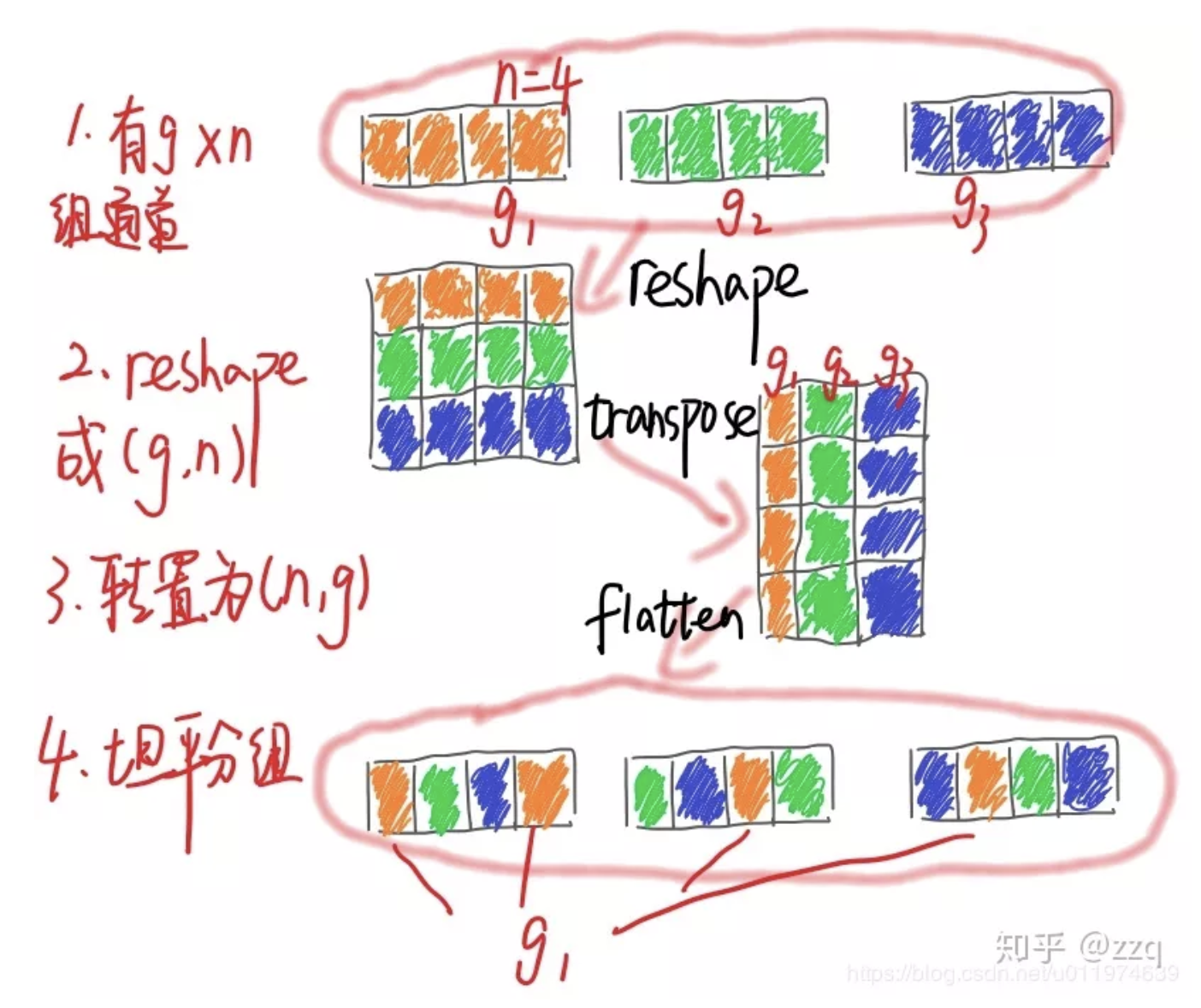
👇展开,转置,平铺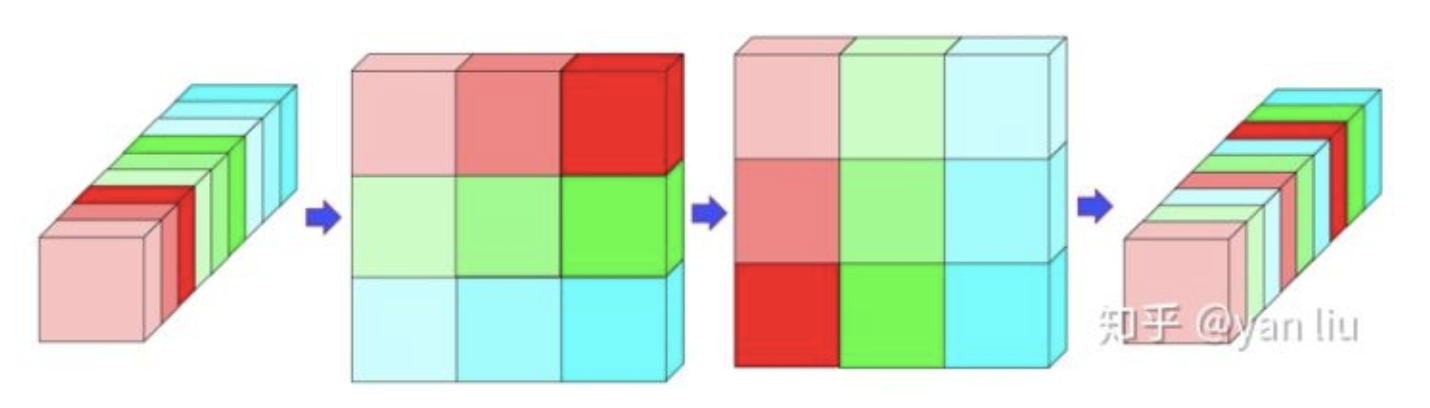
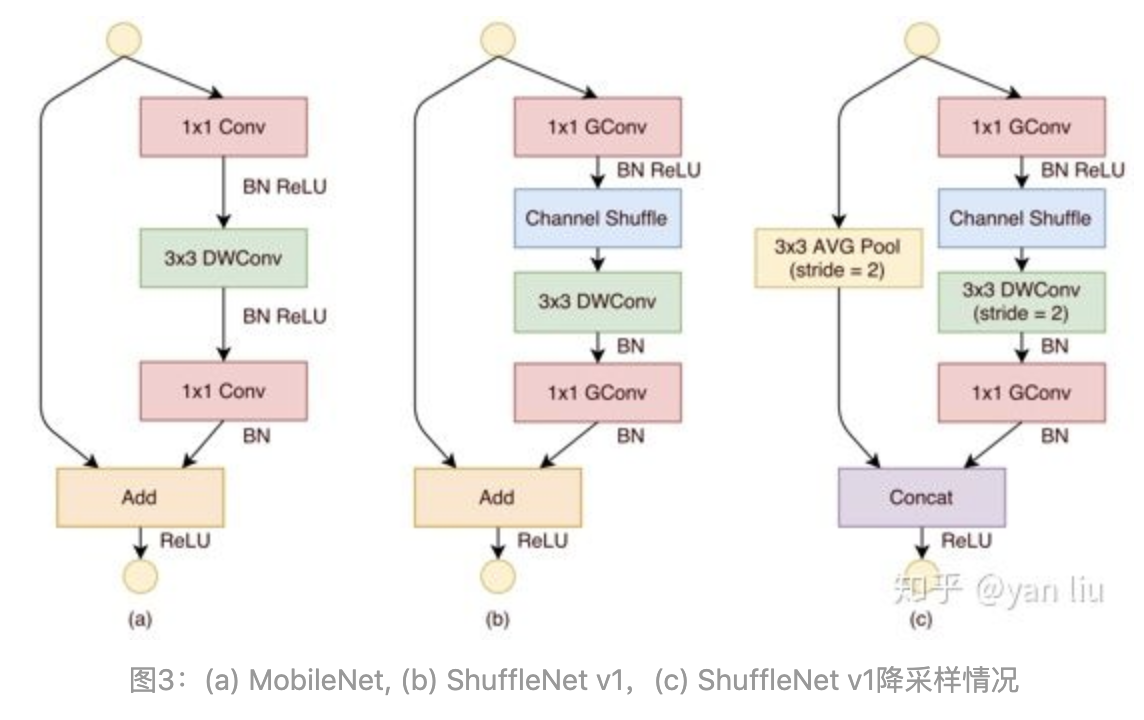
👆对比mobilenet,shufflenet和shufflenet降采样
👆g采用分组卷积,g小;去掉ReLU,减少信息损耗;降采样保证参数量不骤减,需要增加通道数量,采用concat而不是element-wise add
性能评价:MAC访存,GPU并行性
设计准则
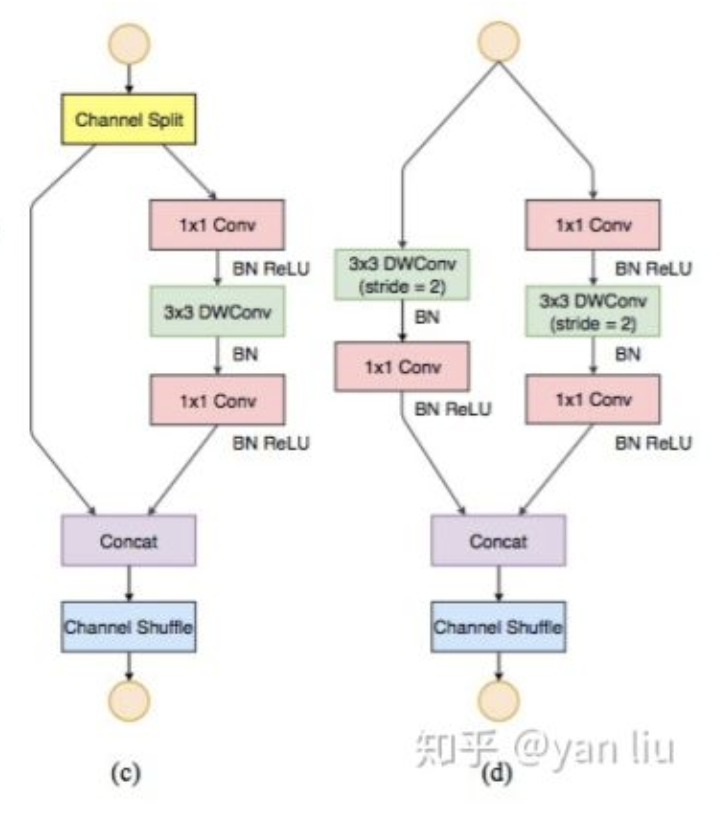
👆shufflenet v2和downsample
增加通道分割,通道分为c1和c2输入到两个分支中,使用concat替代element-wise add
堆叠block的时候,可以将concat, channel-shuffle, channel-split合并为一个element-wise操作
思想—特征重用,上层的feature map直接传入之后的模块,直接映射(shufflenet v2左侧分支)
分块设计思想,模型压缩
1x1卷积代替3x3卷积 3x3卷积输入通道数 Fire Module
两层卷积操作:squeeze 1x1, expand 1x1 + 3x3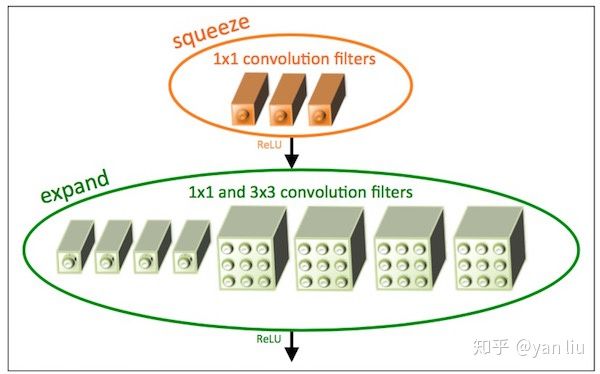
👆👇 squeeze是单分支,expand是二分支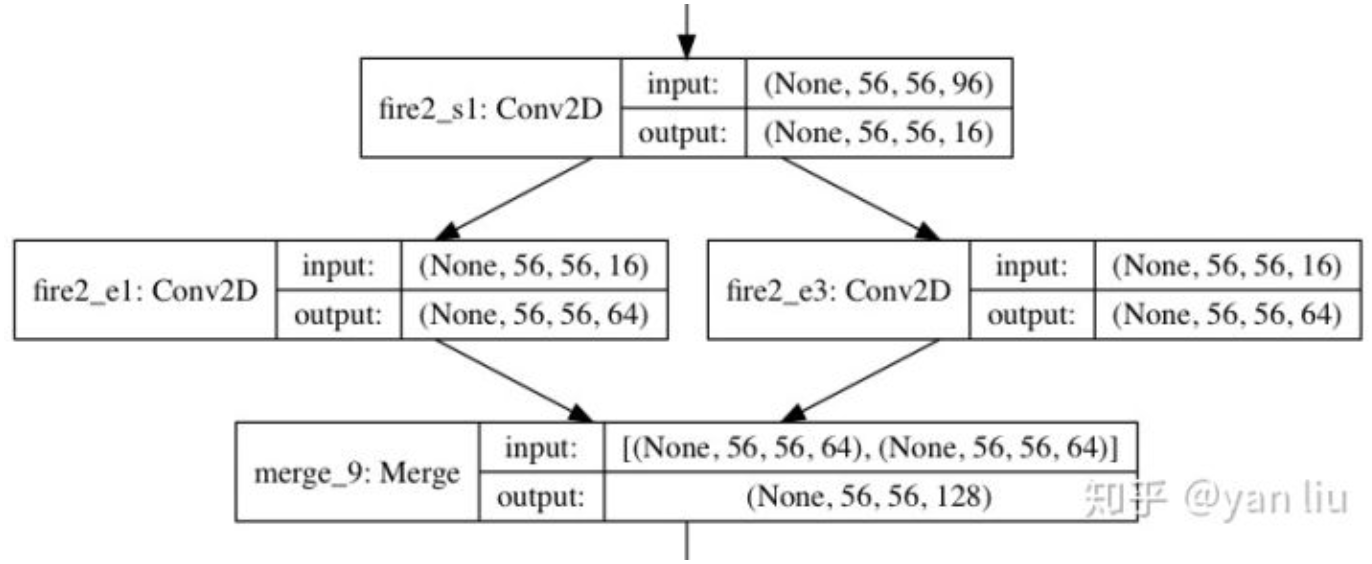
部分3x3变成1x1,参数数量减少,但为获得性能需要加深网络深度,同时并行能力下降,也导致测试时间变长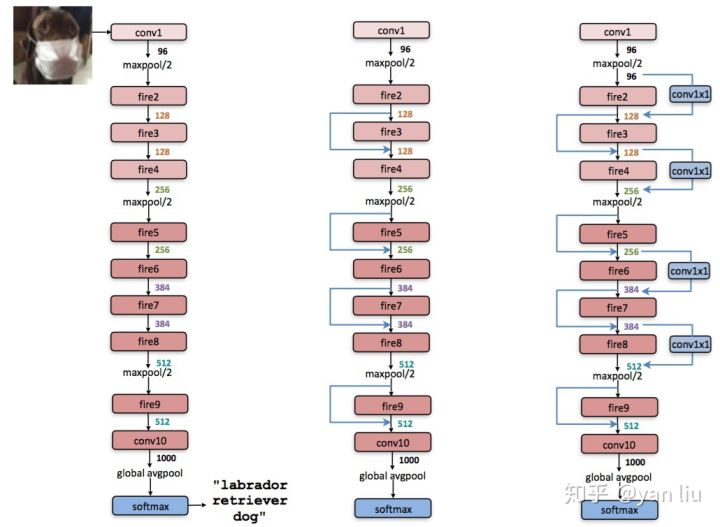
👆网络结构
arXiv
卷积核:空间维度信息,特征维度信息聚集
空间spatial:inception(multiscale),inside-outside(context)
SENet->特征维度,feature channel
Motivation:
特征通道之间的关系:特征重标定(通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征)
Squeeze: global pooling, 顺着空间维度压缩,增加全局空间信息,每一个二维特征图变为一个实数。表示特征通道上全局分布,加上S模块使得靠近输入的层也可以获得全局感受野
Excitation: like gate in RNN. 每个通道生成权重,建模相关性,capture channel-wise dependencies
W的要求 learn non-linear interaction learn a non-mutually-exclusive relationship since we would like to ensure that multiple channels are allowed to be emphasised opposed to one-hot activation
Reweight: multiply with feature map
嵌入Inception:
嵌入ResNet: addition之前进行scale操作,防梯度弥散
Hard Negative Mining in SSD 作为中间结果处理的步骤。只有GT框/和GT框IoU大于阈值的才是正样本(即正确检测框,数量少),其他都是负样本(即错误的检测框,数量大)
为了正负样本数量平衡,防止少量关键的(提升性能)的负样本被大量正样本掩盖而无法被学习/优化到。
解决错误样例太多,正确样例太少,掩盖正确样例的问题。
Hard Negative Mining in SSD: 直接通过根据置信度损失,排序筛选 来选择分类损失最大的负样本(即不是物体但是有最高的分类置信度 -> 困难分类样本迷惑性,丢弃不是物体但分类置信度相对较低 -> 简单错误不严重/不明显),只保留分类置信度损失较大的,人为保证样本数量平衡。
Focal Loss 用于损失函数中
为了能学到困难样例,学到更多,不被简单掩盖。
解决错误样例中,简单的错误样例太多,困难错误样例太少,且求和后掩盖困难的错误样例,而导致检测器学不到困难的错误样例(真正需要学/优化的)。
Focal Loss: 通过给不同置信度的样本增加权重的方法。接近0/1为简单样本,接近0.5为难样本。所以正例x (1-p),负例x p,使用 不确定程度 作为权重。难易的错误都会学,但困难的错误对loss影响更大。

https://rebootingcomputing.ieee.org/lpirc/2019
Winner talk: http://ieeetv.ieee.org/conference-highlights/award-winning-methods-for-lpirc-tao-sheng-lpirc-2018?rf=series|3
http://ieeetv.ieee.org/conference-highlights/deeper-neural-networks-kurt-keutzer-lpirc-2018?rf=series|3
Real Time Object Detection On Low Power Embedded Platforms
1810.01732.pdf
http://www.ee.oulu.fi/~lili/CEFRLatICCV2019.html
DCNN network quantization and compression, energy efficient network architectures, binary hashing techniques and data efficient techniques like meta learning
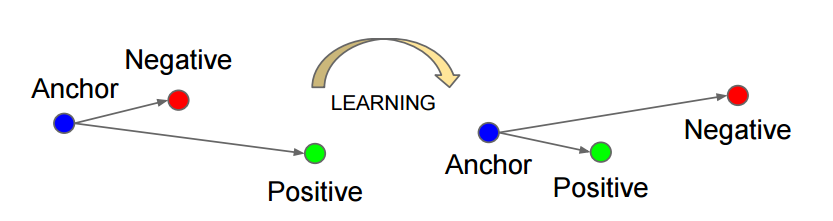
三元组: [anchor, positive, negative] 拉近pos,推远neg
选出B个triplets,只用了B个训练,实际上可以有
6B^2-4B种triplets的组合(B个anchor,pos固定一对一,除此二其他所有都可以为neg,3B-2种;anchor和pos交换乘2)2*B*(3B-2)种
难训练,需要triplet mining。分出hard,semi-hard,easy三种样本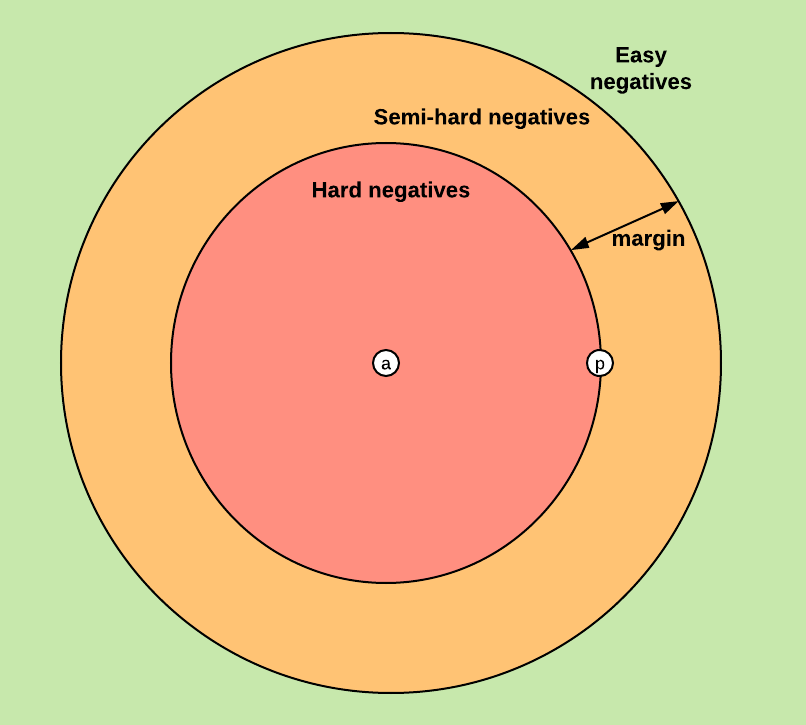
Batch-Hard
选择P个类别(人),每个类别K个样本(照片),PK个样本作为anchor 。每个anchor只选择距离最远的pos和距离最近的neg(最hard)
一共个triplets
Batch-All
选择P个类别(人),每个类别K个样本(照片),PK个样本作为anchor,loss计算所有的pos和所有的neg(和baseline选法相同)
个anchor,每个有
的pos,
个neg(其他所有类别的样本)。一共
个triplets
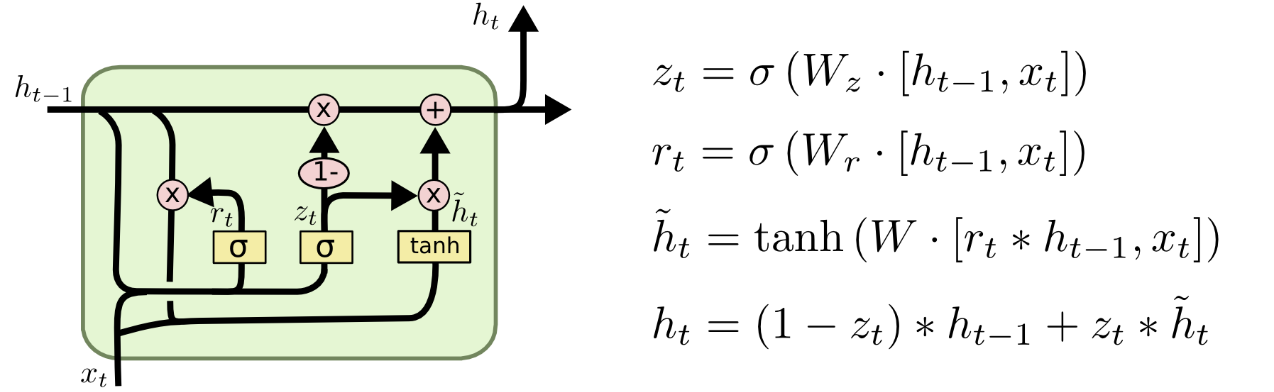
Handling long-term dependencies
LSTM blocks👇
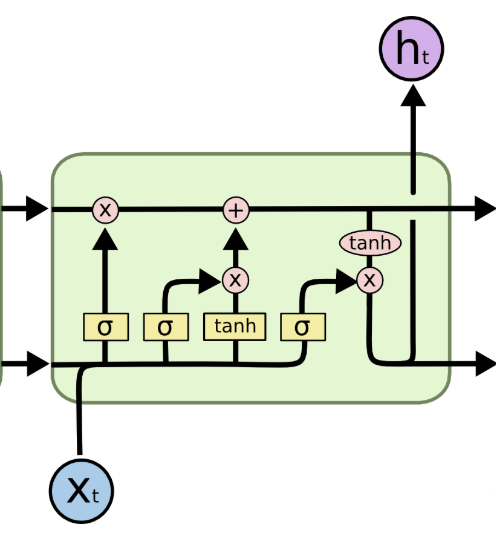
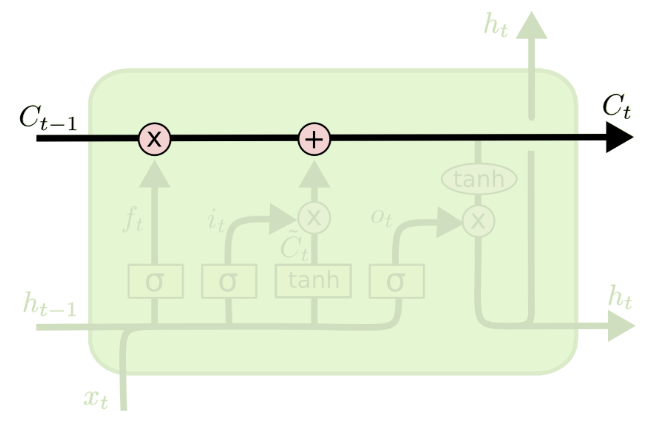
👆Cell state convey information straight down along the entire chain

👆Gate controls whether add/remove information to the cell state
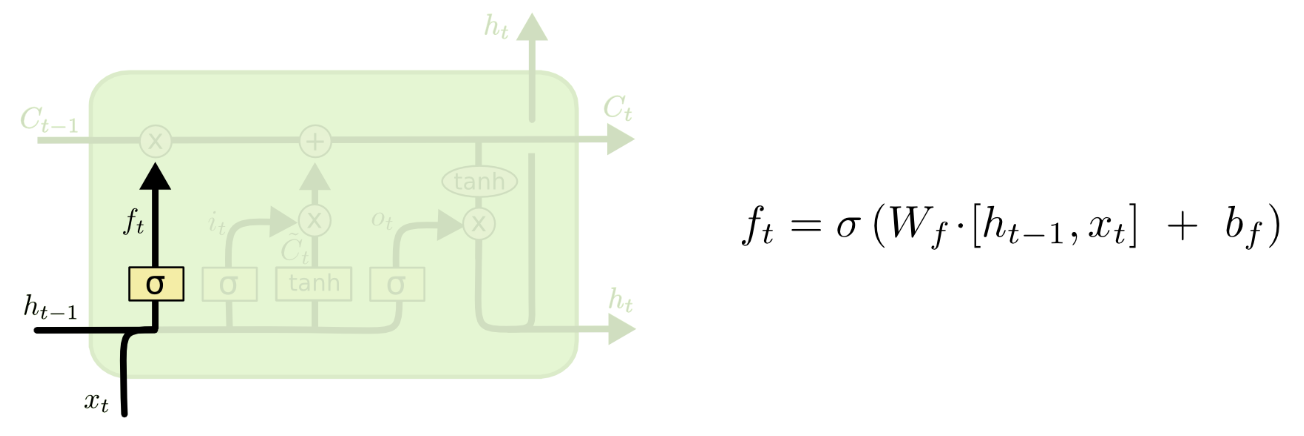
👆Forget Gate: how many last state information() keep/forget.
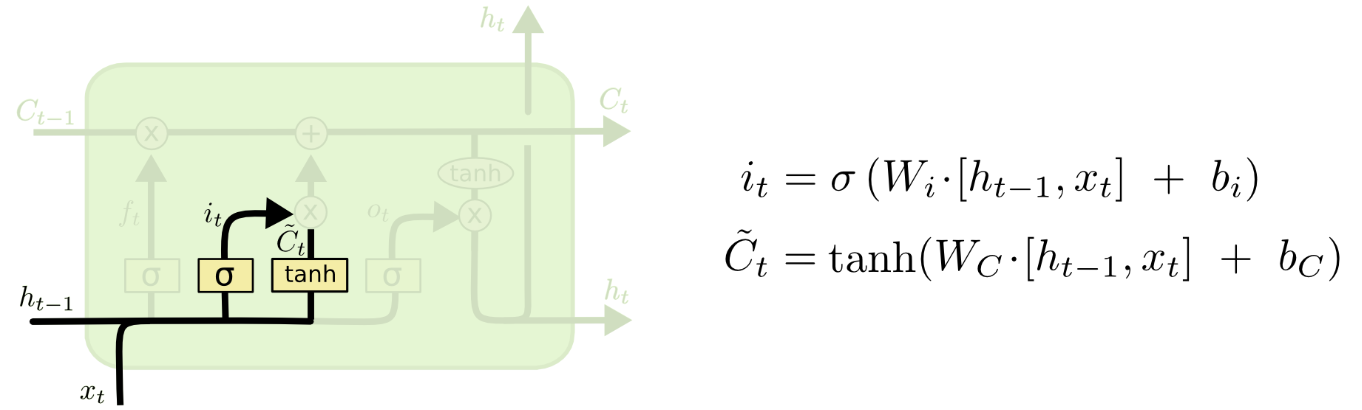
👆Input Gate: what new information we’re going to store in the cell state.
Two parts: sigmoid layer decide which part of values we will update, tanh layer create a vector of new candidate values
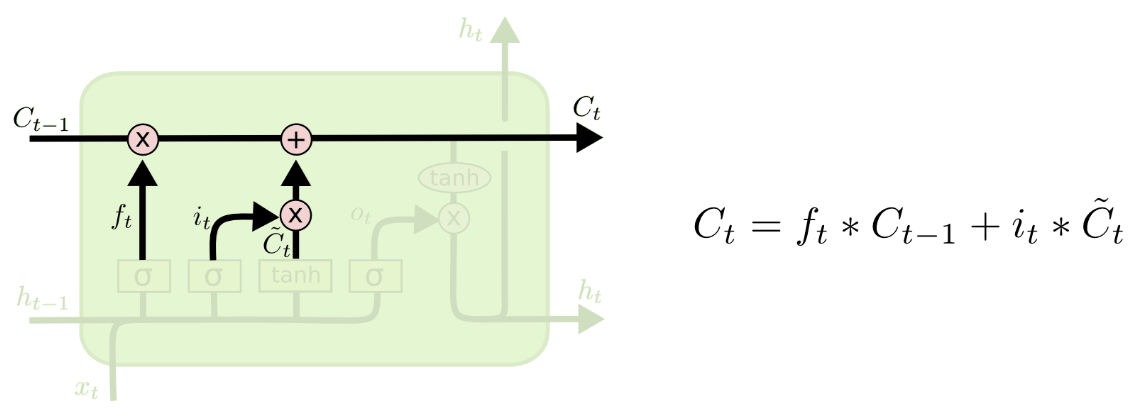
👆Apply to cell state: forget first, then partially add new candidate
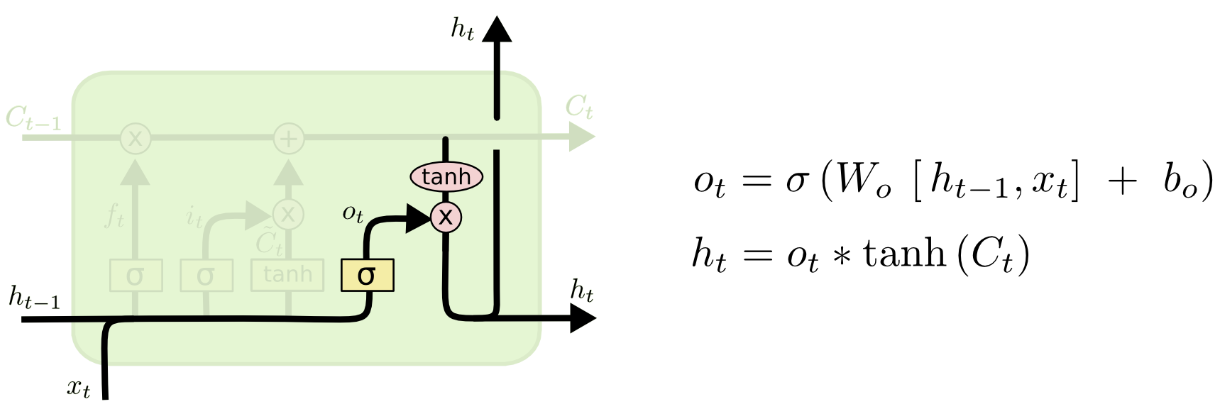
👆Output Gate: decide what we’re going to output
Two parts: sigmoid layer decide which parts of the cell state going to output, tanh layer filters cell state. Multiply them together to get final output.
1. Peephole Connection
gate layer look at the cell state
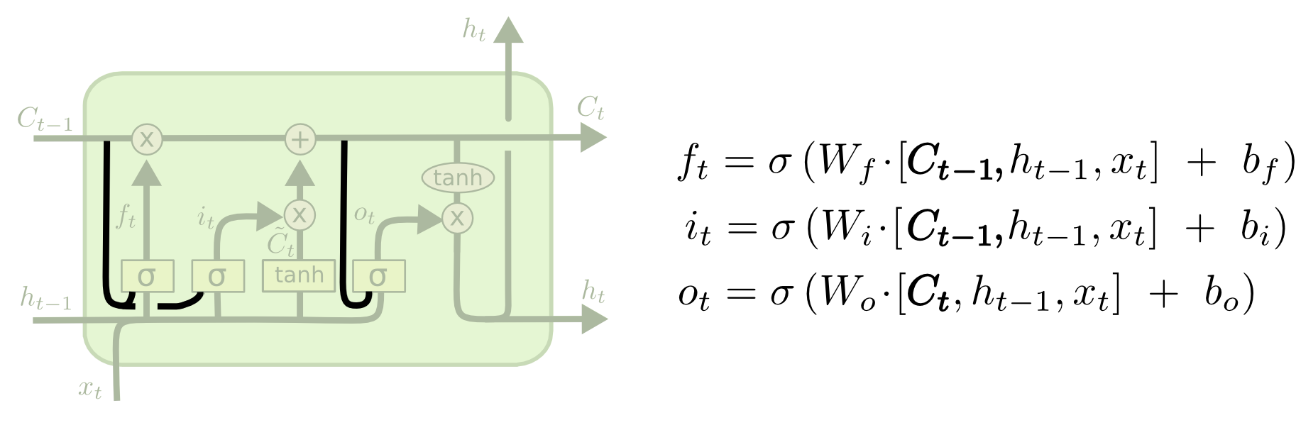
2. Input&Forget Together
make what to forget and what to add together. Only forget when going to input something, only input when we forget.
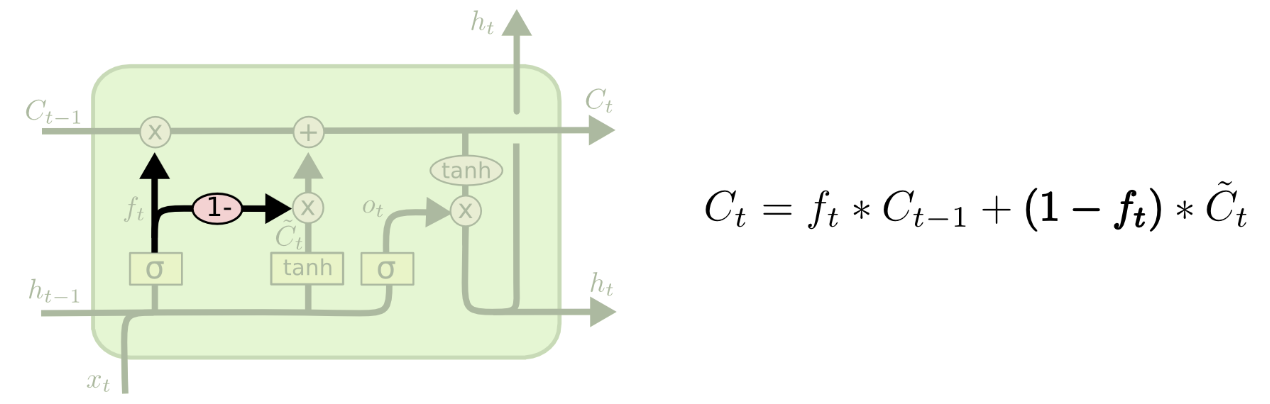
3. Gated Recurrent Unit
Combines the forget and input gated into "update gate". Merge the cell state and the hidden state.
先在小数据集中训练网络单元,再在大数据集中堆叠单元
学习网络中堆叠的网络单元1. Normal cell尺寸不变 2. Reduction cell减尺寸
控制器:一直在执行两个特征图的融合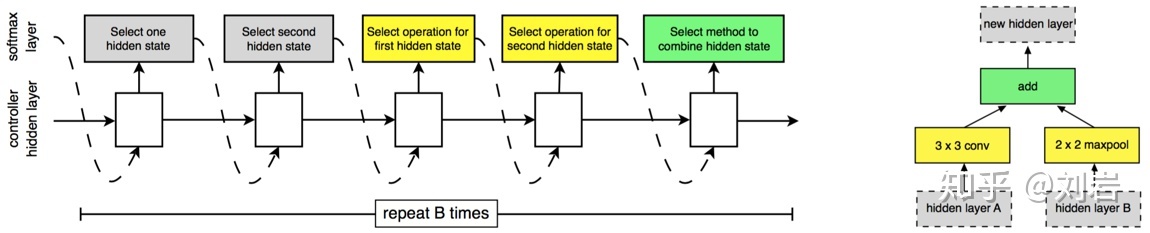
选择第一个feature map和第二个feature map(灰色) 2 ,计算输入的feature map A B(黄色) 2 ,选择操作融合两个feature map(绿色) 1
RNN预测,输出2 x 5 x B其中 normal cell + reduction cell ;每个都有B个块堆叠;每个block有五个输出👆
NASNet迁移学习优化策略为Proximal Policy Optimization(PPO) 👈
提出scheduled drop path,随机丢弃部分分支,增加网络冗余overfitting,类似「Inception」
丢弃概率随时间线型增加,训练次数多容易过拟合
weight sharing inherit its weights from supernet instead of training from scratch
joint optimization weight and architecture
No proxy task or dataset 不需要提前训练小网络/小模块,也不需要从小数据集到大数据集训练
train from scratch 更多迭代,不适用于小数据集
首先训练(pretrain+finetune)一个supernet,然后再supernet空间中找;直接在det任务Vdet上搜索 proxyless 👇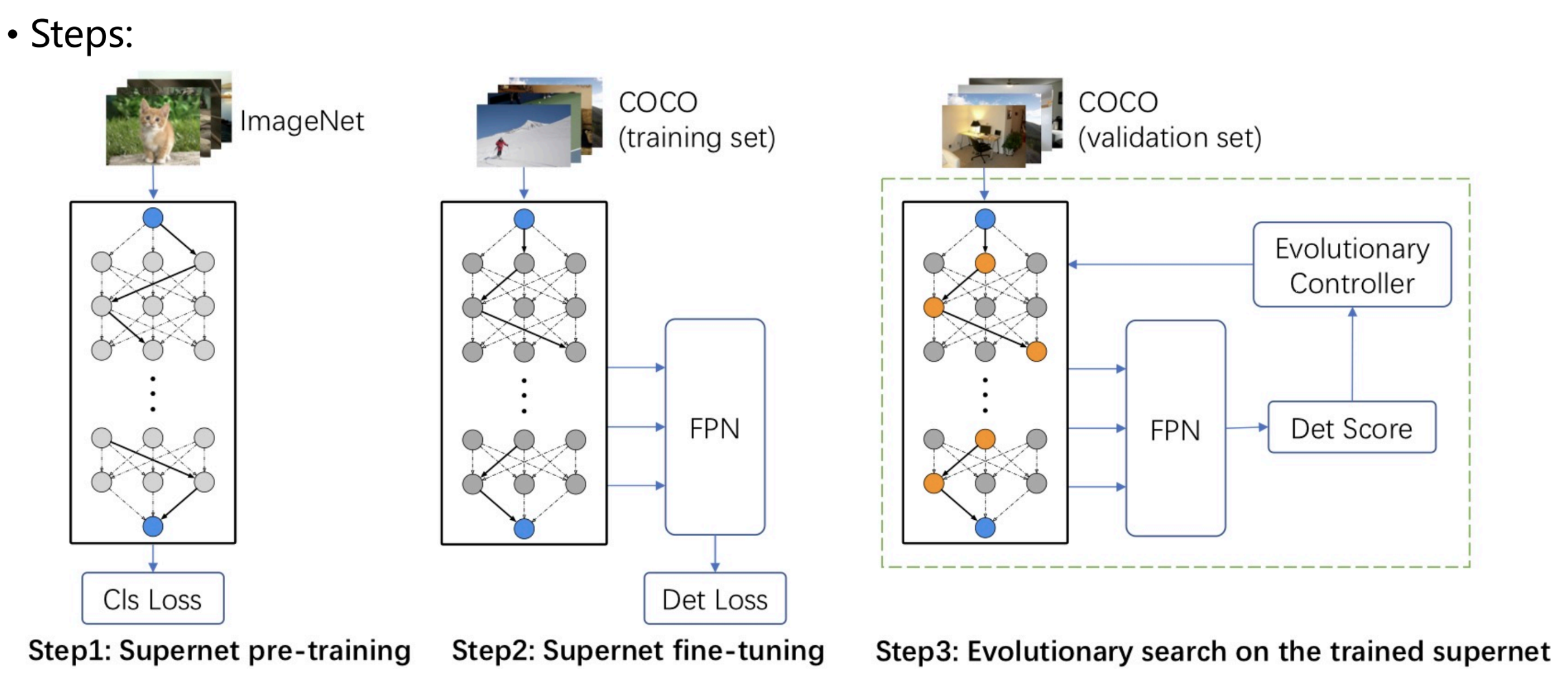
优点:
Decoupling: 没有weight和architecture之间的bias interaction
supernet训好后,直接用val在supernet上搜索 特定应用场景的结构,而不是finetune

Single path sampling: 使训练和测试的配置一致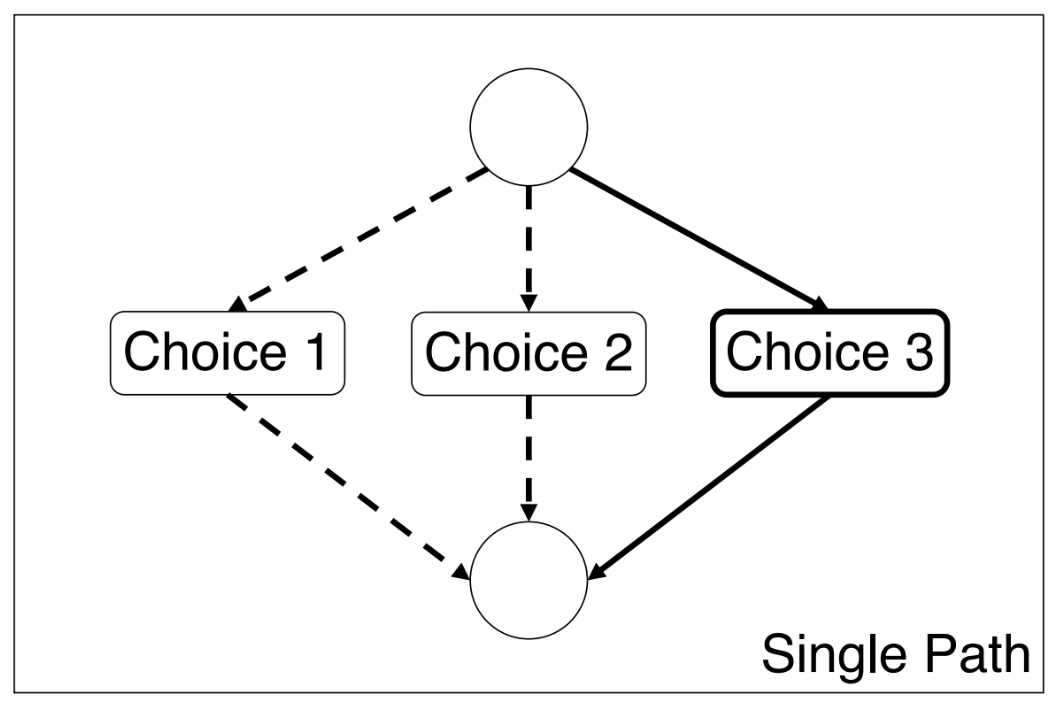
同步BN: BN can not be frozen, 不同path BN的参数不同(GroupNorm速度慢)
遍历每个path,需要重新在trainset上搜集计算BN的mean和var
不用trainset训练子网,而直接在valset上eval
semi-supervised weakly-supervised 使用未标注的数据提升模型性能
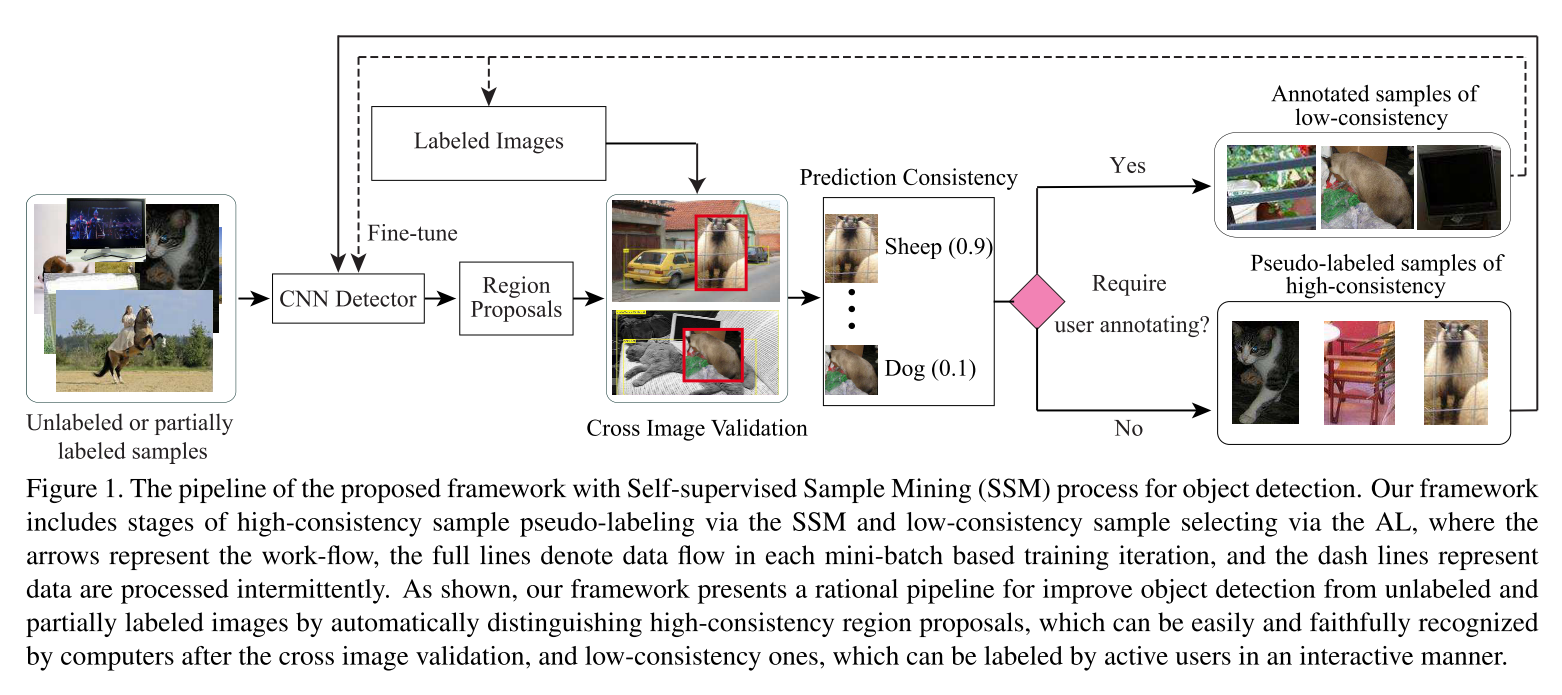
这个框架有两个阶段,分别是通过SSM对高一致性样本进行伪标注阶段和通过AL选择低一致性样本阶段。首先使用已标注的图片对模型进行fine-tune,对未标注或部分标注的图片提取region proposals(未标注样本),把这些 region proposals 粘贴 到已标注的图片中进行交叉图片验证,根据重新预测出来的置信度确定如何对未标注样本进行标注 。对于高一致性样本,直接进行伪标注,对于低一致性样本,通过AL挑选出来,让相关人员进行标注。伪标注的样本用于模型的fine-tune,而新标注的样本添加到已标注的图片中,同时也用于模型的fine-tune
对于好的样本xi,proposal中的内容可以很好的展示j类的特征,粘贴到没有j类的图片中,新生成的图片中的proposal有包含xi的proposal,且具有很大的概率值,高一致性认为之前的样本框准确无错误➡️正样本
任务分类👇
Part detector,针对行人遮挡问题,回归「全身」+「可见」两个框
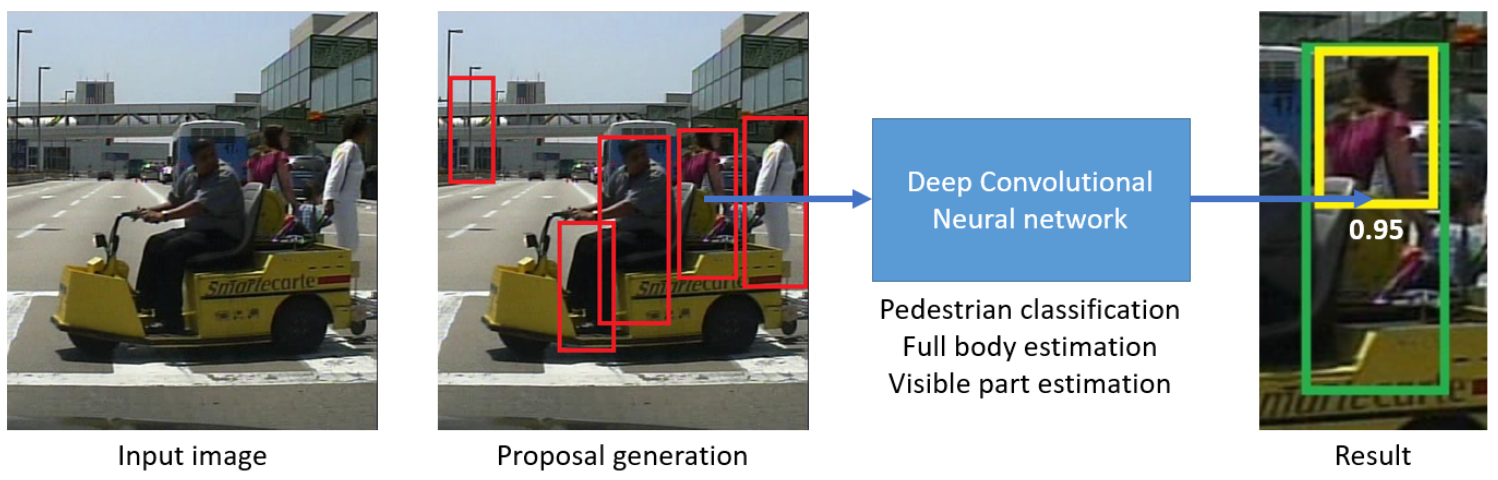
二分支网络:
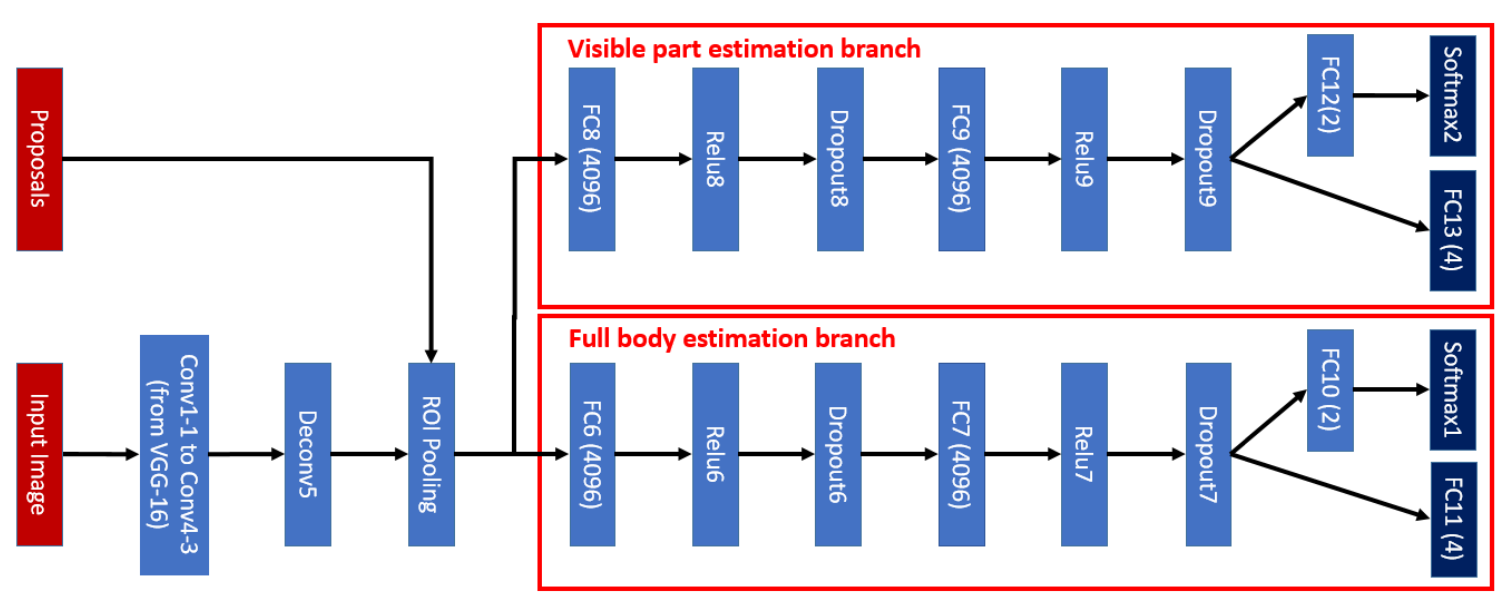
样本标注两个框 (vis/full)。把产生的proposalP={x,y,w,h}和标注框Q=(Full,Vis)match,pos-proposal规则为IoU(P,F)>thresh_1 && C(P,V)>thresh_2. C定义为👇
训练样本X=(Img, P, cate=1, F, V),regression target为👇
Neg-proposal=1.background 2.poorly aligned proposal 回归w,h -> 0
Why should force visible part of neg-proposal shrink? 「vis分支对pos和neg都处理」 #没懂
If the visible part estimation branch is trained to only regress visible parts for positive pedestrian proposals, the training of this branch would be dominated by pedestrian examples which are non-occluded or slightly occluded. For these pedestrian proposals, their ground-truth visible part and full body regions overlap largely. As a result, the estimated visible part region of a negative pedestrian proposal is often close to its estimated full body re- gion and the difference between the two branches after training would not be as large as the case in which the visible part regions of negative examples are forced to shrink to their centers.
不对负样本处理,则对负样本的预测结果两个分支相同「full分支对所有样本回归到GT,vis分支对正样本回归到GT,对负样本回归到0」
👆蓝色框,和full(GT)重合度高,但和vis重合度低。在Faster-RCNN中被认为pos,在本文中认为neg。更强的评价标准
网络量化
Network compression: sparsity, quantization, and binarization
使用低精度的浮点运算,相比于静态确定每个weight和activation的精度,本文根据网络输入(例如背景不需要精确计算)动态确定 Tuning the bit width per layer
Computes most features with low-precision arithmetic ops and only updates few important features to a high-precision
用在shufflenet v2上提升26% ImageNet分类精度
ReId的occlude问题,使不同目标的检测框远离「类似triplet loss」

采用检测框架中bbox回归loss
和周围GT目标框远离,远离IoU大且没有匹配的目标框
即
类似IoU loss(不是IoU而是IoG:若最小化IoU,则预测框越大IoU越小)
where
使预测框集中在匹配的目标附近,而不会偏移到临近物体
预测框和其他预测框远离(匹配上不同物体的目标框)
防止不同物体的两个检测框被NMS过滤掉
输入, 输出
,参数
和
(parameters, 每个特征图一对)
Where ,
均值和方差 (batch statistics)
统计不同样本在同一个channel同一位置数据的均值方差 (reduce at batch dim hwc)
反向传播时,由于均值和方差是输入的函数
where ,
,
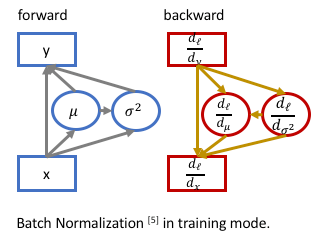
Ref: https://kevinzakka.github.io/2016/09/14/batch_normalization/
https://kiddie92.github.io/2019/03/06/卷积神经网络之Batch-Normalization(一):How?
https://www.cnblogs.com/shine-lee/p/11989612.html
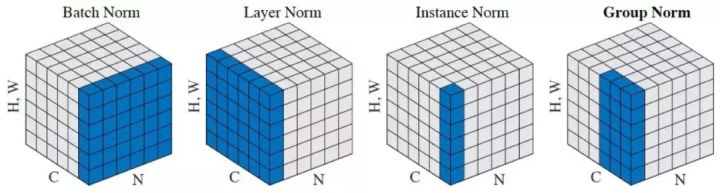
==Batch Norm==对一个batch中所有样本的同一channel计算统计量,受batch_size影响
==Layer Norm==对单个样本计算统计量,用于RNN
==Instance Norm==单样本单通道计算,风格迁移
==Group Norm==对通道分组,解决BN依赖batch_size的问题
同一层特征通道之间关联性强,特征具有相同分布,可以group
Switchable Normalization计算BN、LN、IN三种的统计量,然后加权作为SN的均值
和方差
「解决batch_size影响,自适应不同任务」
norm👇
加权权重归一化👇
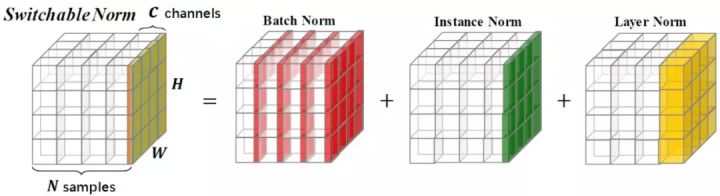
LN, IN正常计算,BN采用batch average方式,具体过程是,冻结所有的参数,从训练集中随机抽取一定数量的样本,计算SN的均值和方差,然后使用他们的平均值作为BN的统计值
Ref: https://zhuanlan.zhihu.com/p/39296570
多卡训练时,传统BN只在单GPU上归一化,改成多个GPU之间同步信息;性能明显提升
通过计算均值和方差的中间量和
,只需同步一次
根据
FP 计算均值和方差 ,
BP 计算,
和
,都可以单卡上计算,只同步一次
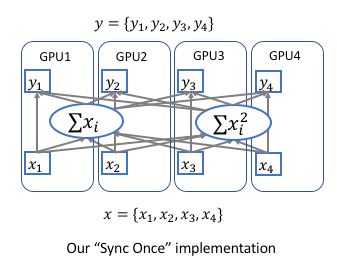
Ref: https://hangzhang.org/PyTorch-Encoding/notes/syncbn.html
Improvement: MABN(移动平均+减少统计量+中心化权重) https://arxiv.org/abs/2001.06838
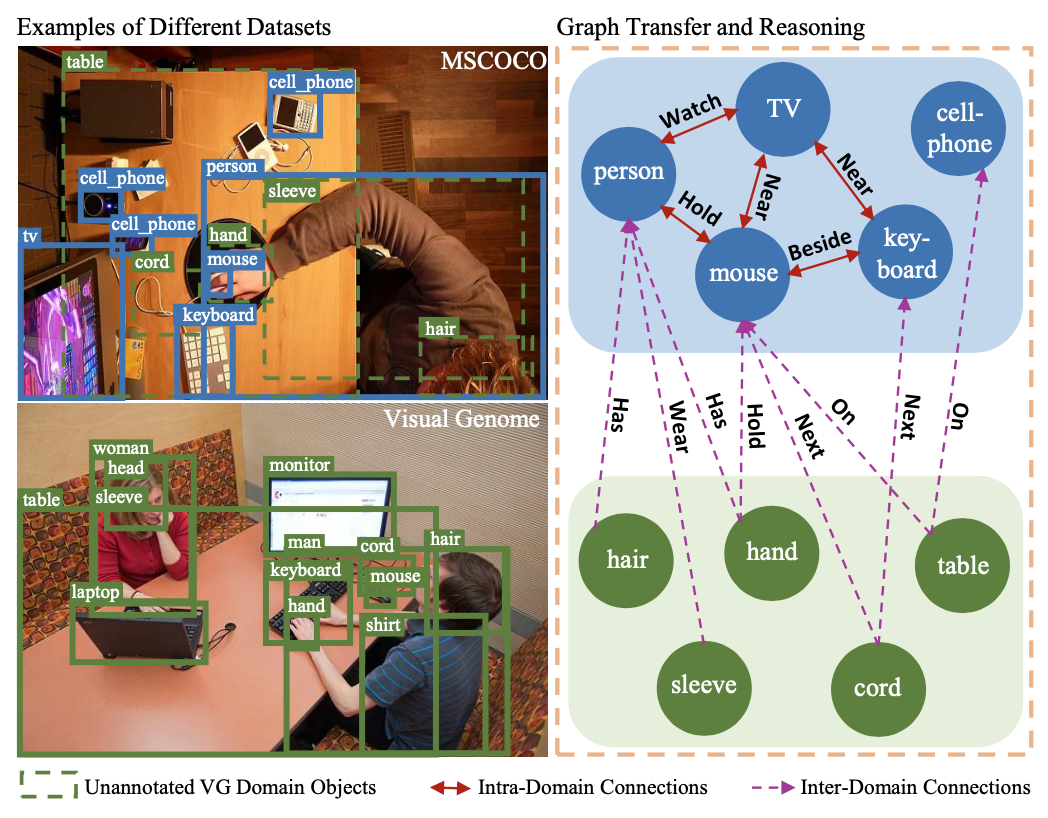
解决检测域迁移,不同域类别关系推理()reasoning)和迁移(transfer)
Intra-Domain Reasoning: 域内部图表示上传播,类别之间相关性
Inter-Graph Transfer: 域间迁移,不同域类别之间层次关系
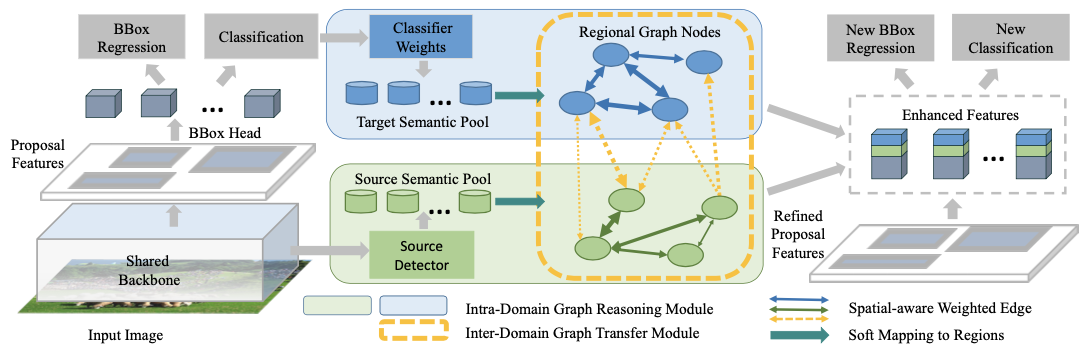
使用backbone计算proposal feature (global semantic pool)
构建区域关系图,节点表示region proposal,边表示关系。proposal之间关联关系(attribute similarities, interactions)
学习边权重,只保留重要proposal关系的稀疏邻接矩阵
propsoal feature在GCN计算,和原始特征concat,得到新的global semantic pool
sharing common features between categories via connected edges such as similar attributes & relations.
improve feature rep. by adding adaptive contexts from global semantic pool
bridge the gap between domains
源域用上述模块构建,构建
,GCN计算从源域到目标域迁移,concat源域特征
划分group,conv
group conv,分组进行通道shuffle
常见网络压缩方式
量化权重weight quantization
低精度表示,易性能下降
知识蒸馏knowledge distillation
易受教师网络影响
网络剪枝network pruning
去掉部分unimportant网络参数 (eg. filter pruning algo.)
参数weight norm来判断是否prune「L1正则化可增加sparsity」
使用GroupConv使通道间稀疏连接
使用learning-based通道shuffle增强inter-group info flow
步骤:使用structured regularization训练大模型 将部分conv转为group conv
finetune恢复精度
卷积核权重值认为input output channel之间关联性
卷积groupable:权重可以排列成block diagonal
👇一般conv的weights(channel之间关联程度)

👇groupable conv,一个channel只和同组内几个channel有高响应,即block diagonal(👇有两个block,cardinality=2,每个block中的对角块0惩罚,block中左下右上块0.5惩罚,block块外1惩罚,见下下图)

变为学习==划分channel==问题,损失函数惩罚左下右上没有被zero-out的权重,使用coordinate descent计算(线性规划问题,or optimal transport)

channel shuffle解释👇

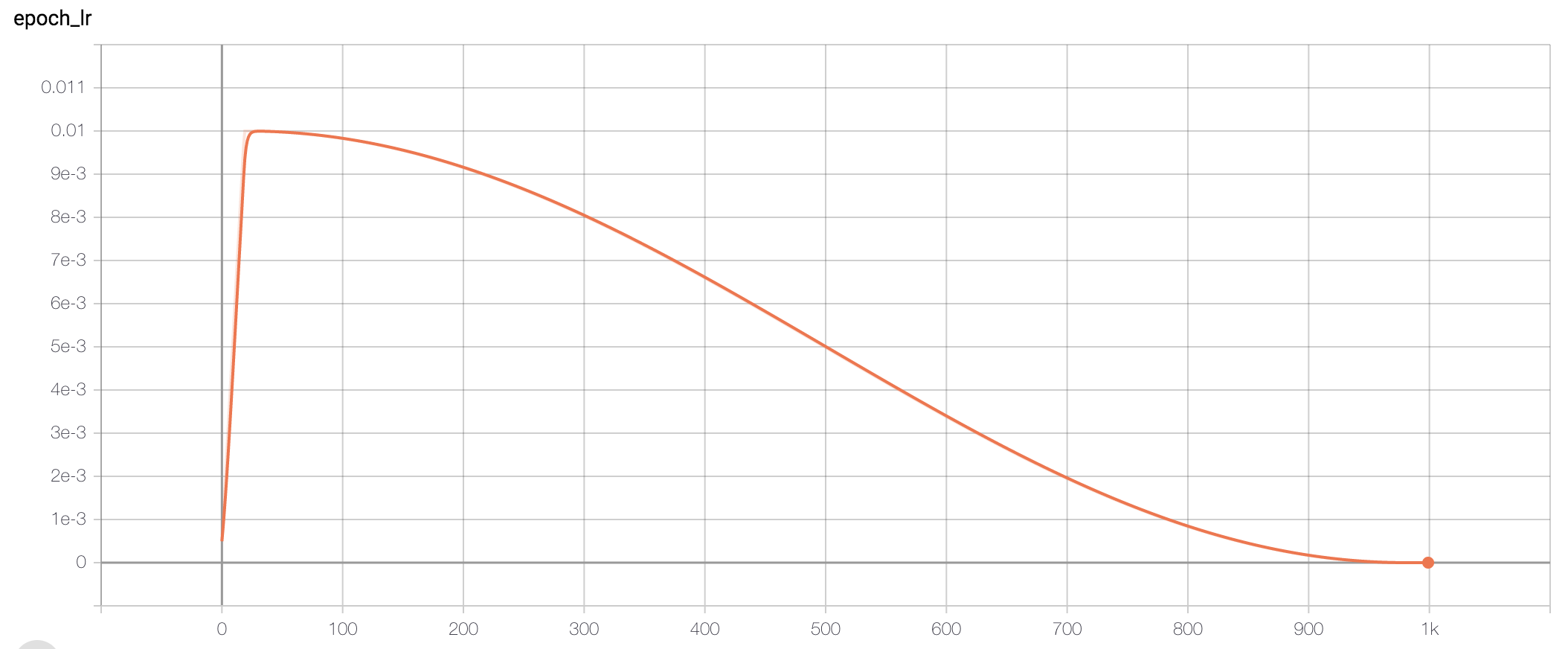
常见为step devay
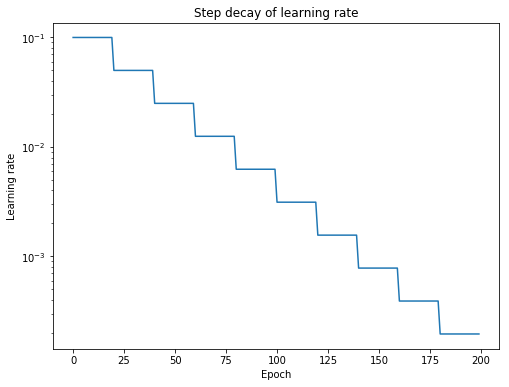
Ref: https://medium.com/@scorrea92/cosine-learning-rate-decay-e8b50aa455b
分类任务中学习如何缩放,spatially-sample
Attention:先LR用saliency network产生attention map,然后映射到HR图片上使用
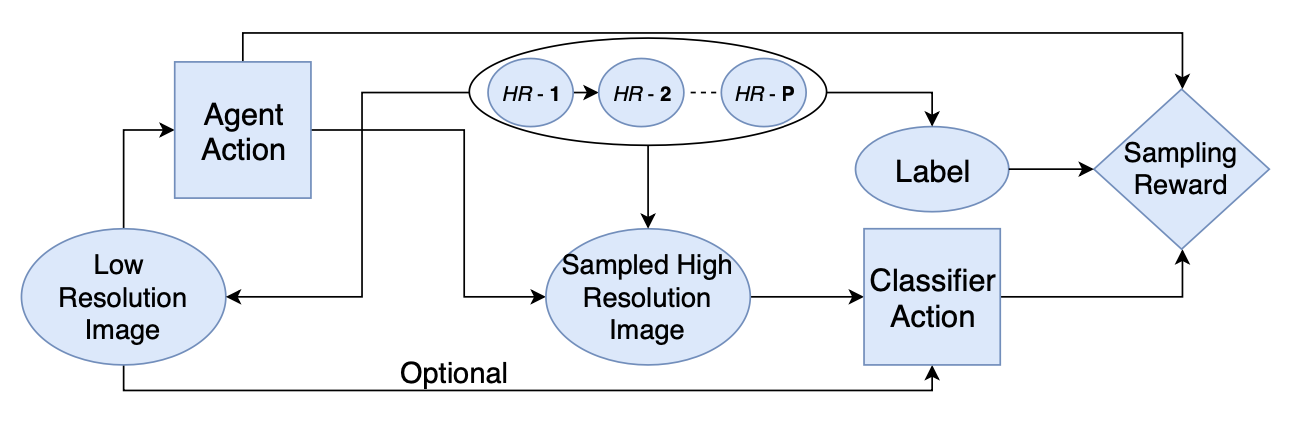
学习:根据LR图像决策sample哪些HR图像。sample成本和准确率tradeoff
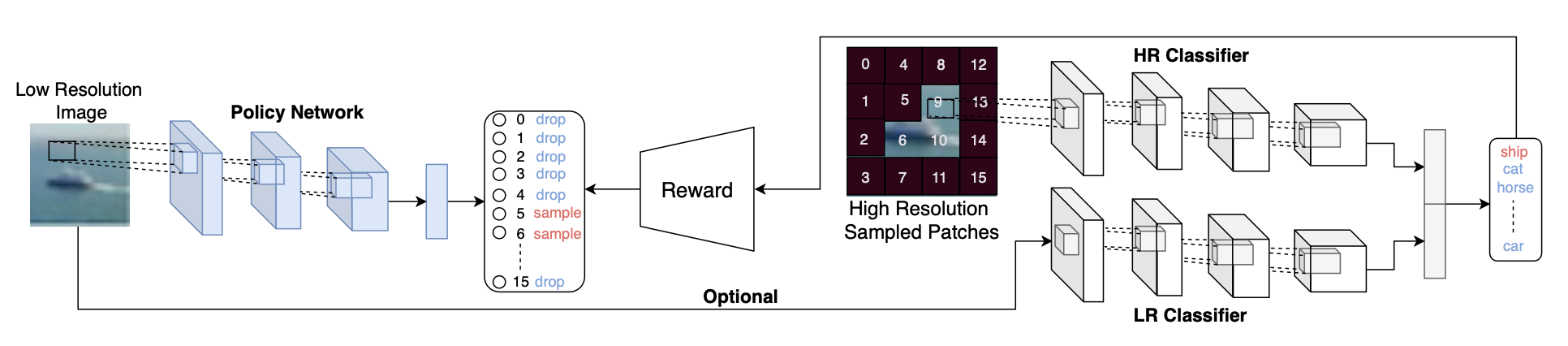
适用于遥感/高分辨率图片分类/检测(?)
衡量两个set之间的距离
Jaccard index:
Distance:
Ref: https://www.statisticshowto.datasciencecentral.com/jaccard-index/
针对数据集中错误标注,使[0, 1]变成[0.2, 0.8],减弱正样本的loss,冲淡错误信号的影响
Large logit gaps combined with the bounded gradient will make the model less adaptive and too confident about its predictions.
二值神经网络,使用Information Bottleneck理论简化网络(作为一个损失函数)
检测任务看作,图片到特征到类别位置
Information Bottleneck理论
目标为
最小化特征提取的互信息(信息增益,知道A对确定B的影响),最大化检测网络的互信息
互信息可以看作网络的信息损失,互信息大,信息损失大。前半部分为网络提取足够的特征,后半部分为只检测有效的框,去除冗余信息
损失函数:
其中为IB理论的优化目标,类别多项式分布,位置正态分布,
通过采样得到
为减少一张图中目标的自信息(
为第i个物体的objectness)。把一张图的多个物体分为多个block,使
目标conf和为1,减少目标数量/假阳性,即让一张图内不要有多个high objectness的物体,限制为只有少量物体「适用于每张照片目标较少的数据集」
常见网络训练为ERM:训练数据为经验,记住所有样本,不能泛化
数据增强可以理解为VRM (vicinal risk minimization):领域风险最小化,构造数据集样本的领域值,学习领域的小变化,但方式dataset-dependent&heuristic
提出利用线性插值产生新的标注样本对,混合到数据集中训练「增加有噪声的样本」
其中和
为数据集中「标注-样本」对,
实例分割,级联,mask和box同时采用cascade方式refine
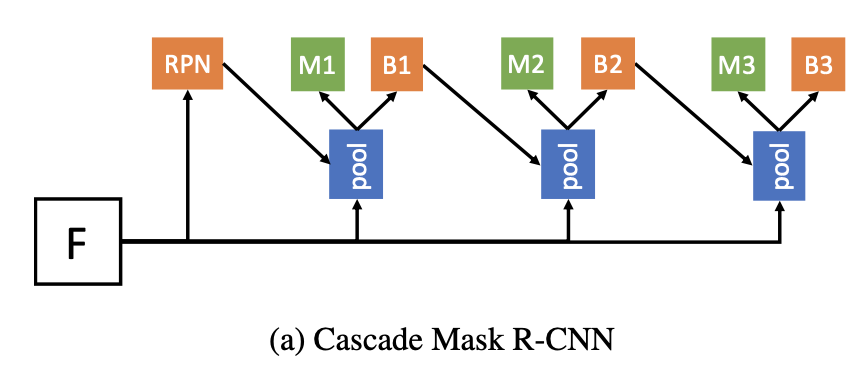
👆级联refine,box和mask两个分支。接受上一stage回归后的box作为输入,预测新的mask和box
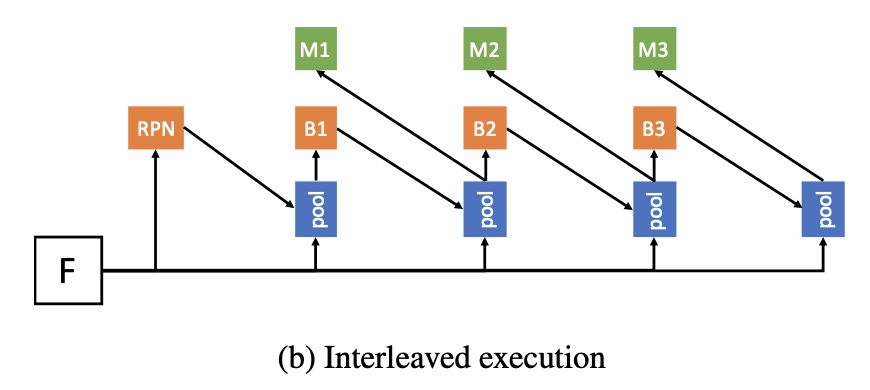
👆mask1是box1经过pool之后得到的,mask和box两个分支有交互,boxmask
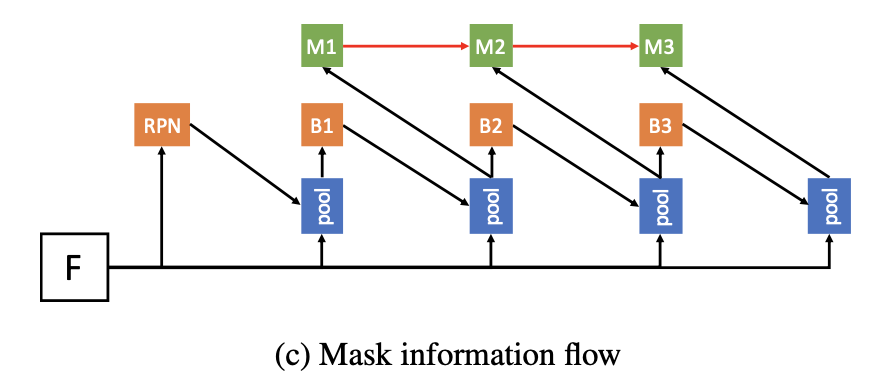
👆mask之间也进行信息交互
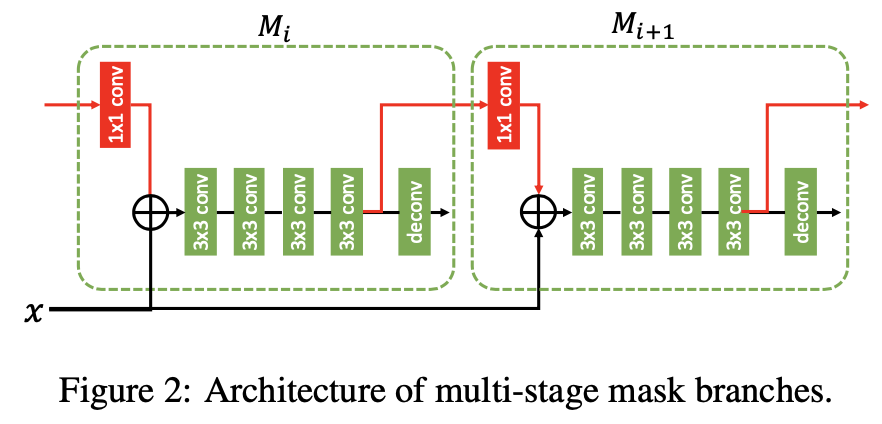
交互方式👆,上一个stage的mask经过1x1 conv,然后和box_pool相加,上一个stage的mask和box共同产生下一个stage的mask
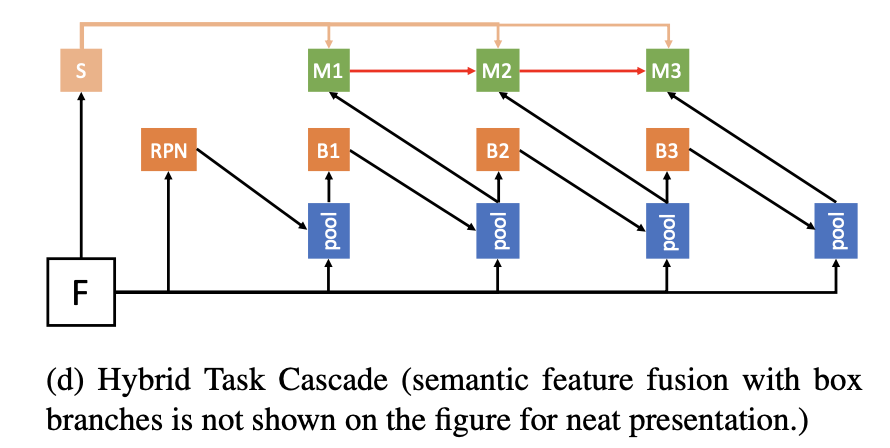
👆最后加入语义信息分支
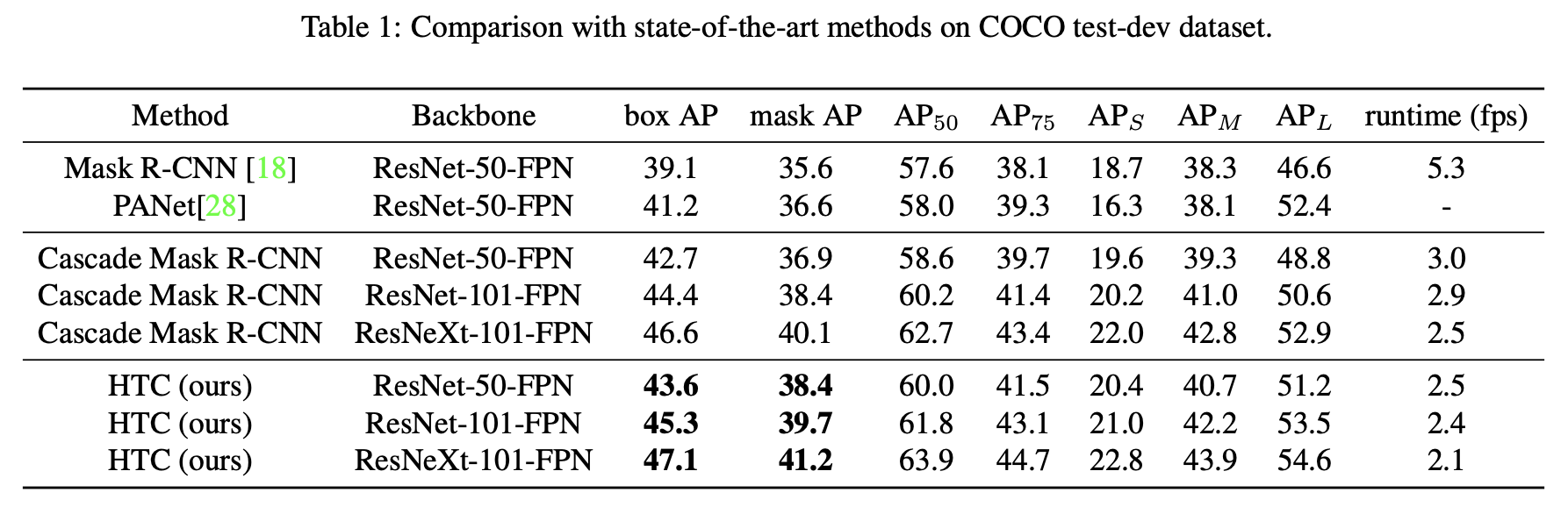
性能极强,速度慢👇
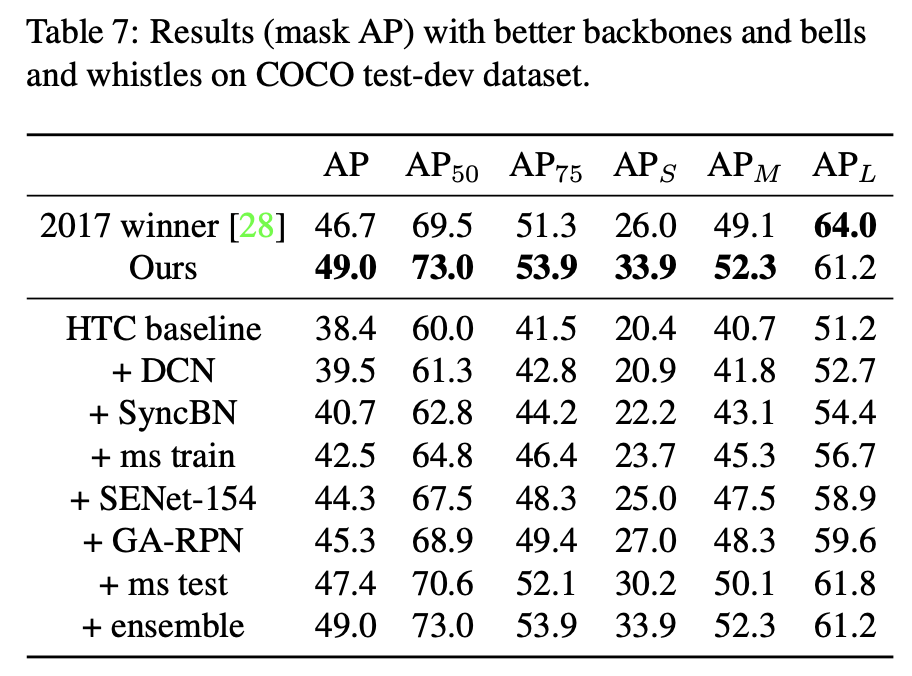
多个弱学习器集成组合为更精确更鲁棒模型
单个模型 或为高偏置(低自由度模型),或为高方差(高自由度模型)。根据弱学习器的性能选择集成方法,高偏置使用compose,高方差使用average
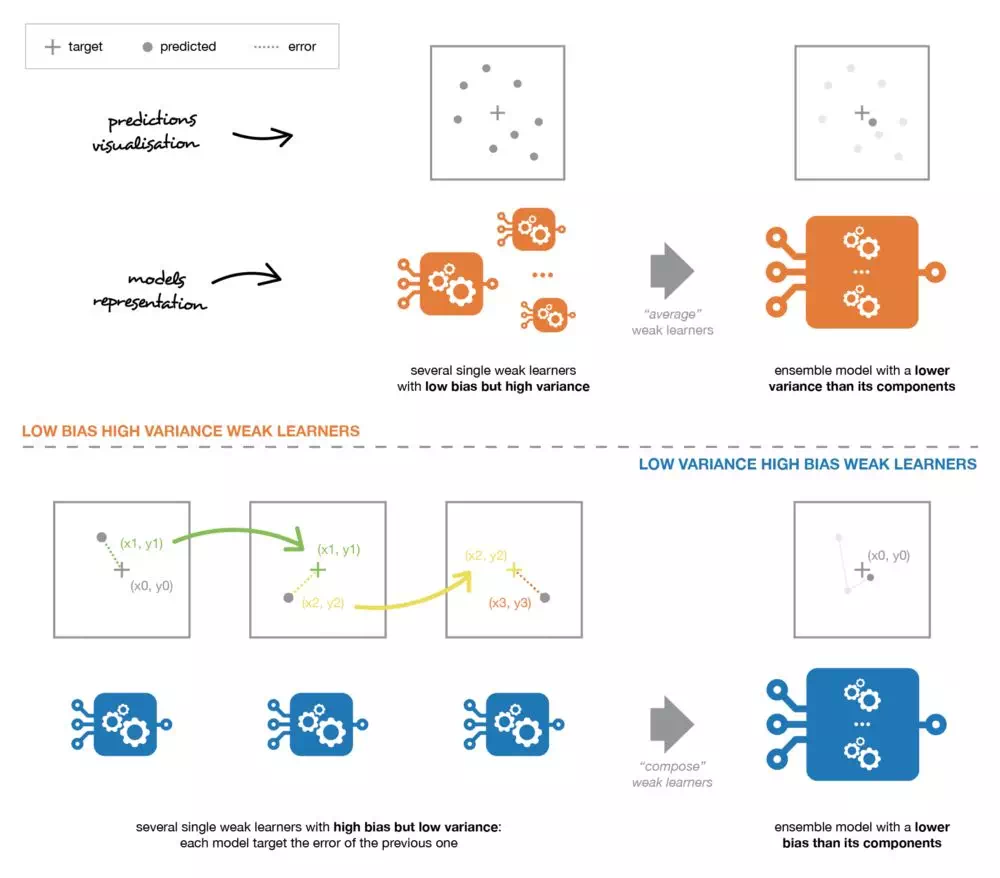
并行的独立学习多个同质弱学习器,目标为减小方差
如:随机森林
迭代的拟合模型,串行,目标为减小偏置
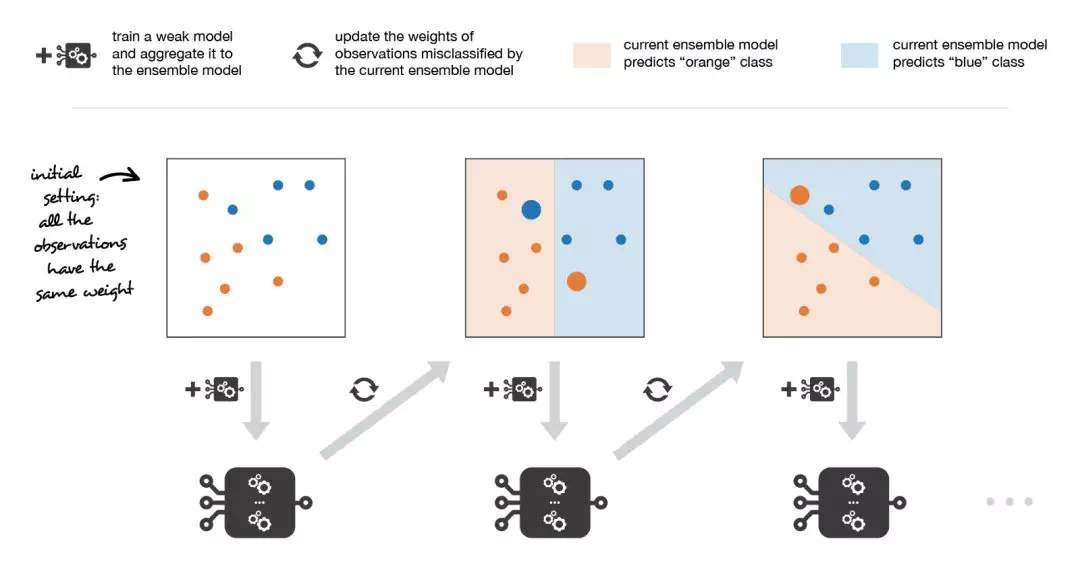
如:AdaBoost,GBDT
多个弱学习器堆叠,学习元模型将其组合「例如:KNN+Logistic-Reg+SVM,NN将其组合」
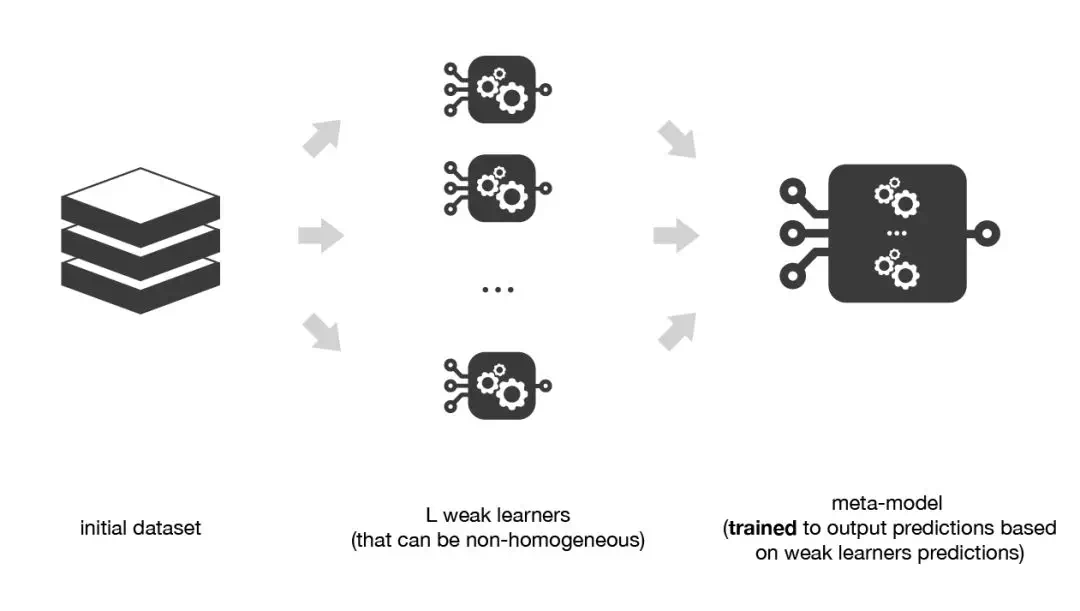
Ref: https://www.jiqizhixin.com/articles/2019-05-15-15, https://zhuanlan.zhihu.com/p/27689464
在 Group Conv基础上改进卷积 heterogeneous
拆分为不规则的操作
增大感受野,大范围的context
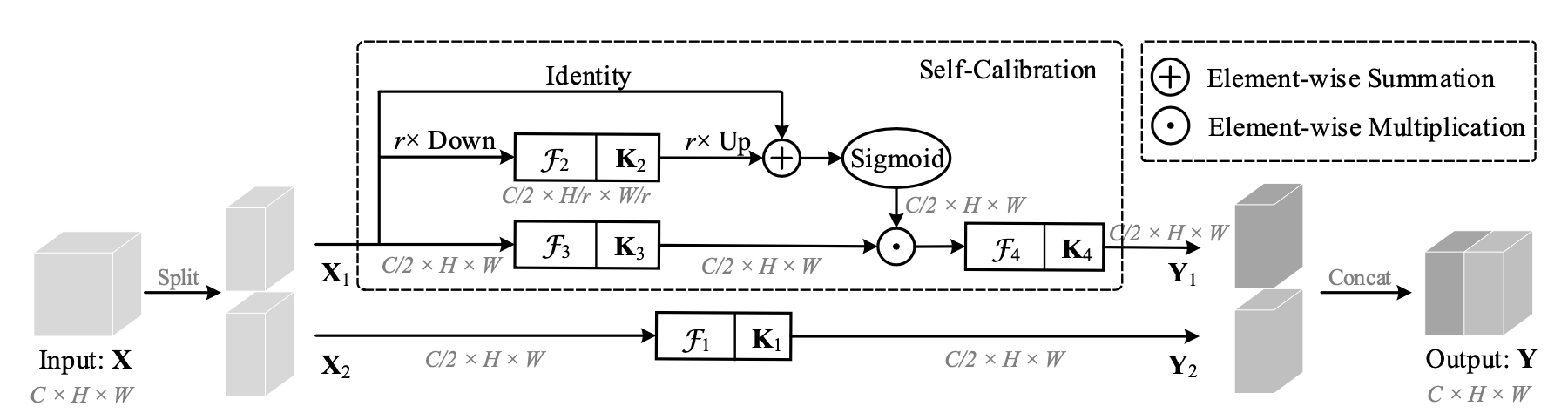
首先把原始特征图通道上分为两部分 Group Conv
为Self-Calibration分支,
为卷积分支
分别在small scale的latent空间和large scale的original空间进行卷积操作,再融合calibration
Latent空间:
下采样减小尺度
小尺度上卷积并upsample回原尺度
Original空间和latent空间融合:
for sigmoid function
Final output:
Self-calibration在小尺度操作,可以扩大感受野 (Regional context),融合多尺度的信息
带状pooling,各向异性特征,分割任务
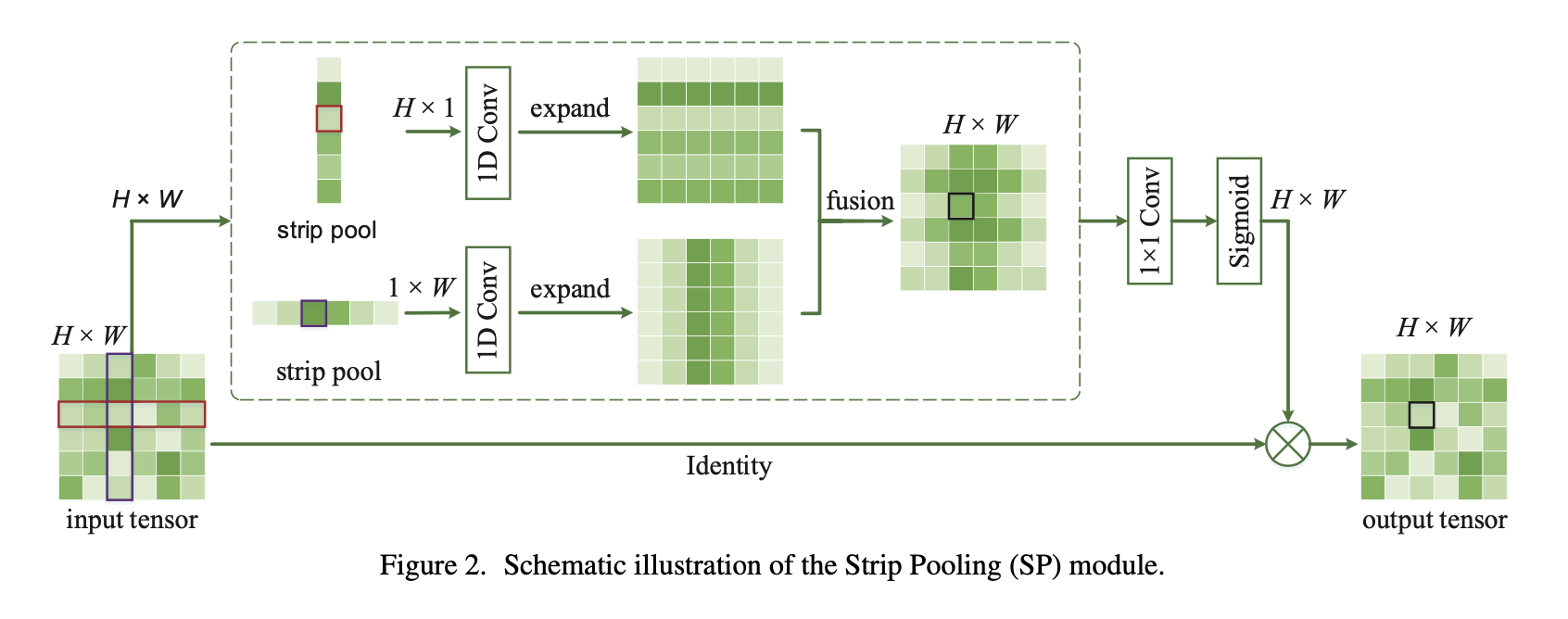
长条形感受野,<font color=#FF0000 >行感受野</font>在每一行的所有列进行average,压缩到1列,pooling结果为列向量;<font color=#0000FF >列感受野</font>在每一列的所有行average,压缩到一行,pooling结果为行向量
然后扩展成原图尺寸,再fusion
对长条状物体又帮助,可以集合任意两个位置的dependency (long-range)
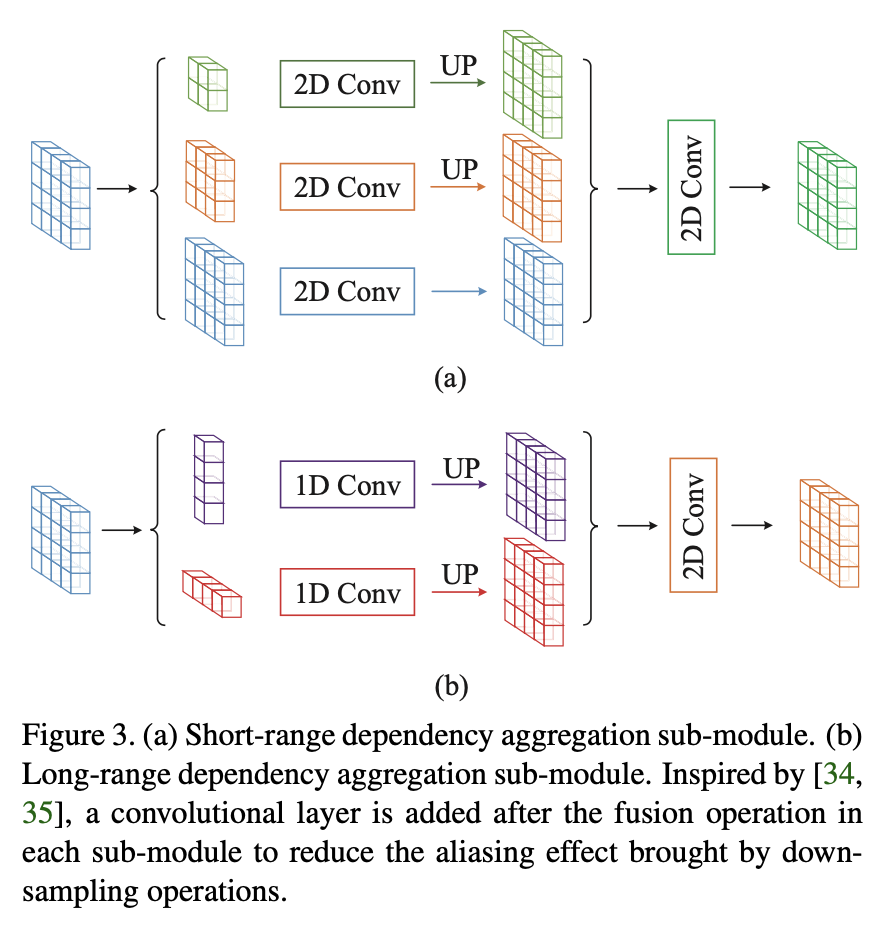

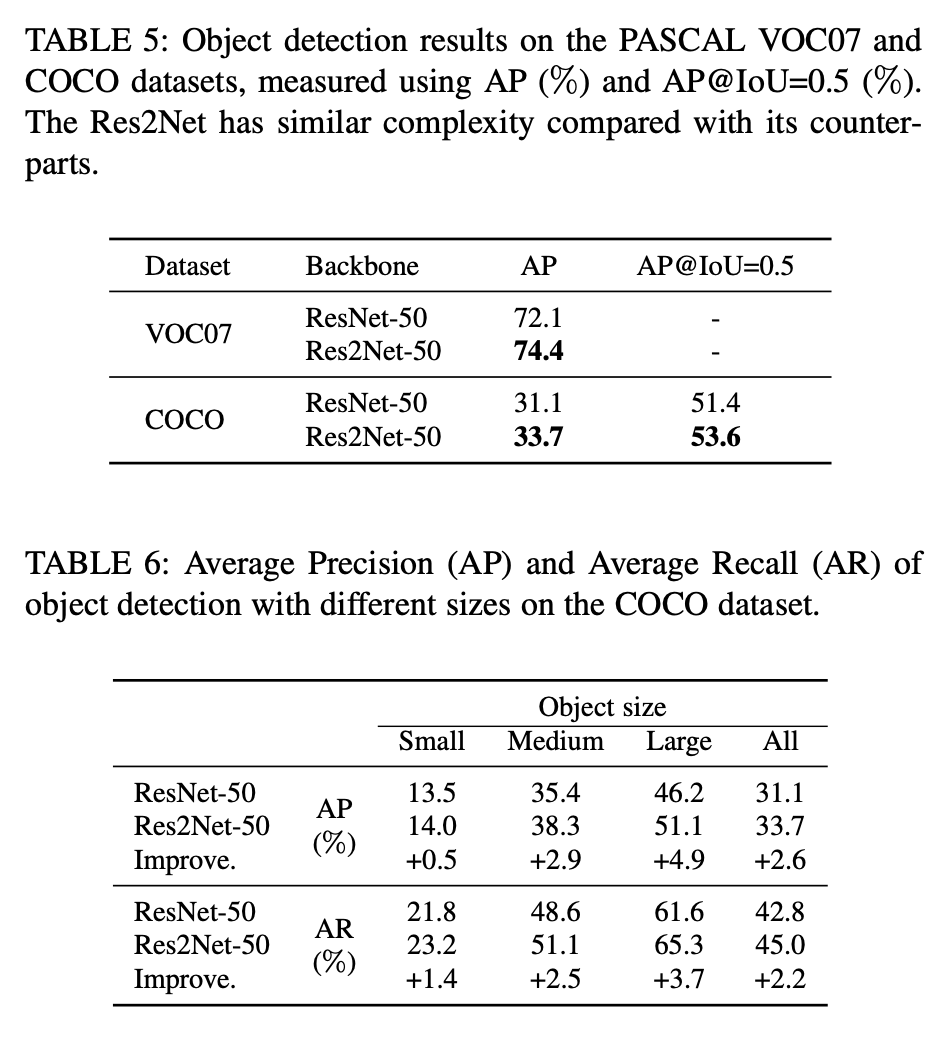
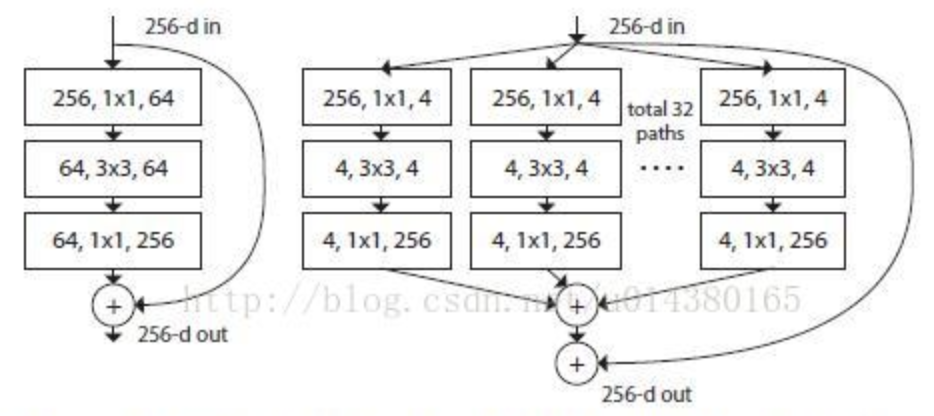
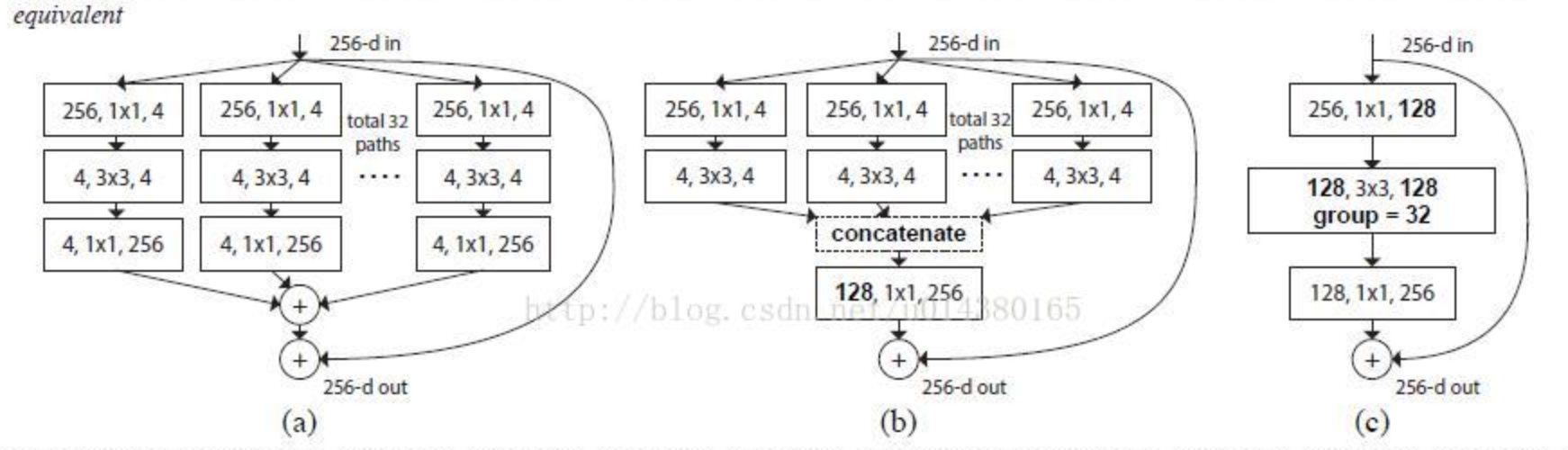
多尺度卷积,通用,但速度有下降;基于ResNet,可用于ResNeXt
将一个卷积分成不同深度的操作,获得不同尺度的空间/语义信息
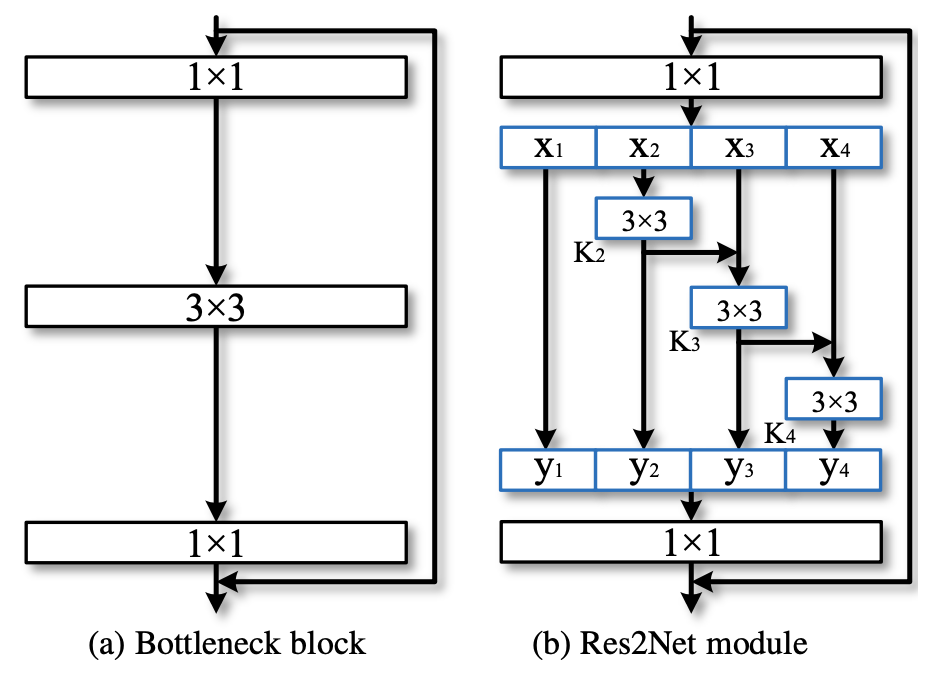
相比ResNet,减少参数量提性能。同样GFLOPS,速度会慢,但精度更高;同样精度下,速度更快。