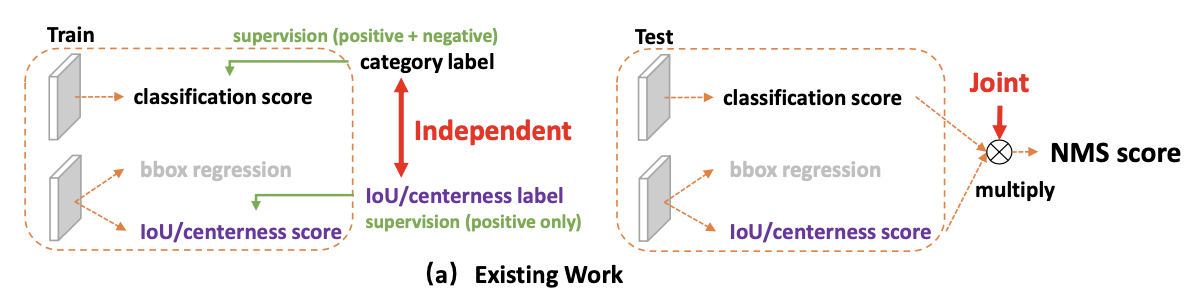
Label-assignment, 选择正/负样本点(anchor-free)需要动态确定,且正负样本点损失加权。权重:cate+物体计算
center prior: 训练时固定先验
(instance) confidence map: 根据数据动态调整
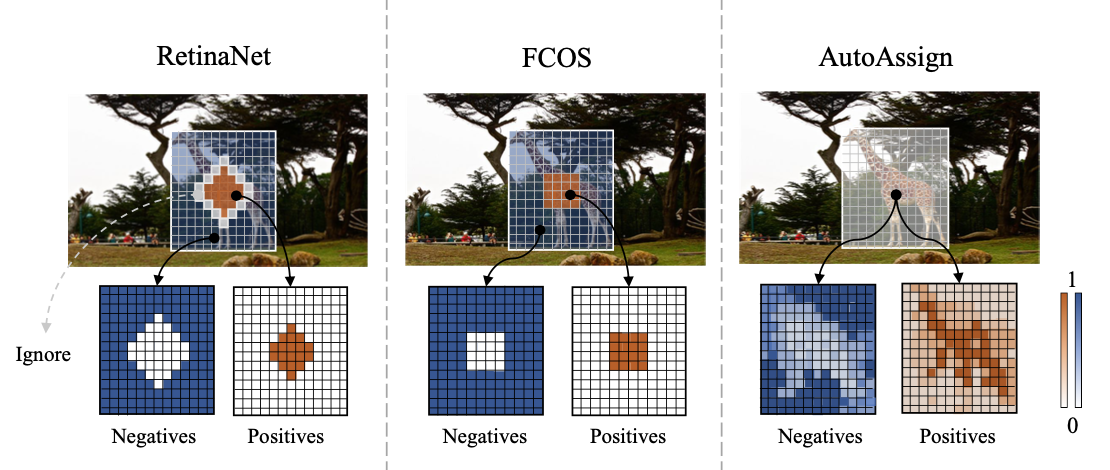
之前空间上采样正负样本的方法为 1. IoU 2. 物体框中心固定区域都为正样本。但存在物体框中部分区域没有物体,且固定区域无法优化 obstacle caused by feature shifting when backgrounds are sampled as positives may decrease the performance.
提出根据category&instance信息动态产生pos/neg weight map [differentiable/data-driven]

👆更加dynamic
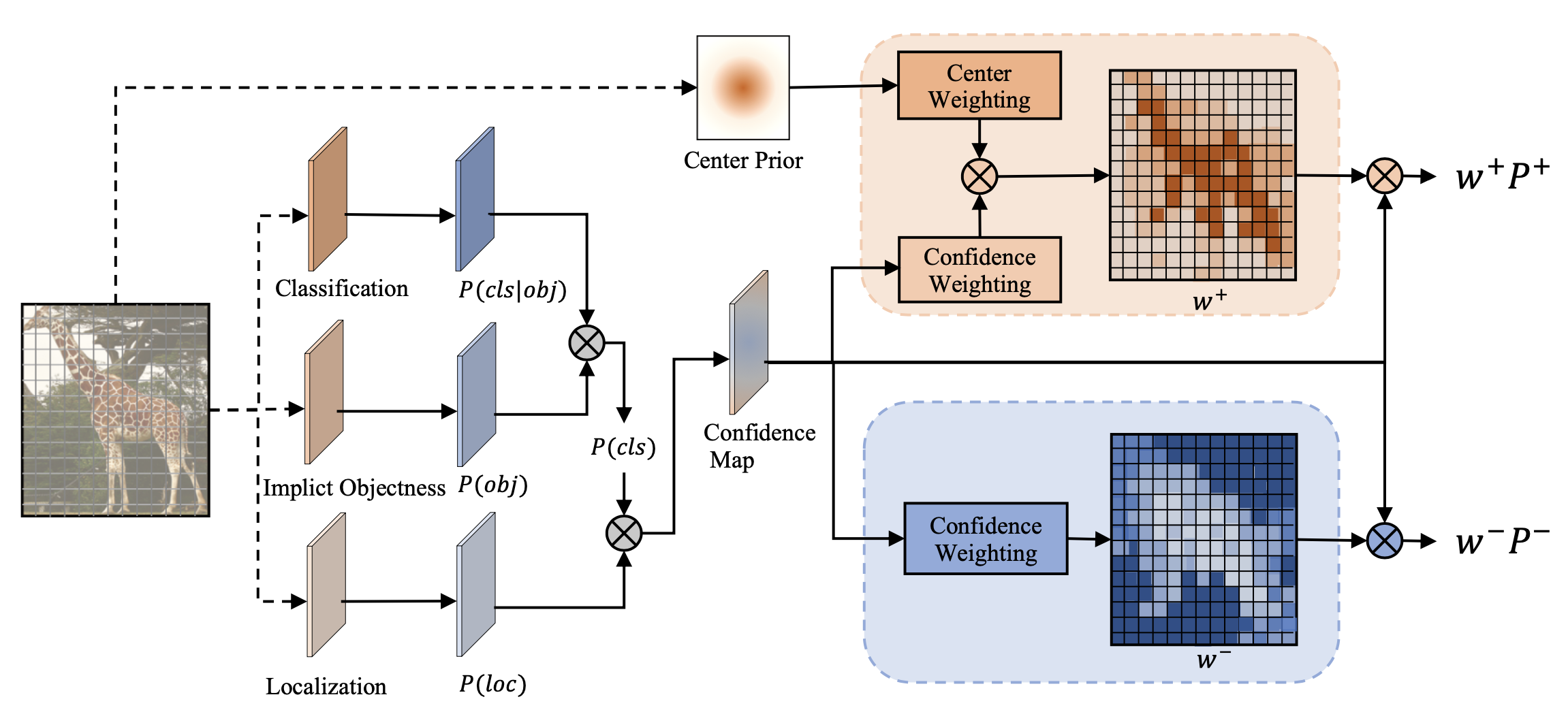
通过Center Weighting + Confidence Weighting得到Weight Map()
学习一个category-wise分布,即带参数的Gaussian-shape weighting function,用在FPN的每一层。
,其中
为某个位置的xy偏移量,一种类别有一组
center prior可以增加类别的先验分布信息,防止网络冷启动后出现过拟合(不断优化第一次w高的点)
由于conf weighting作用的是每个GT-Box中所有点,所以应用center prior时已知类别
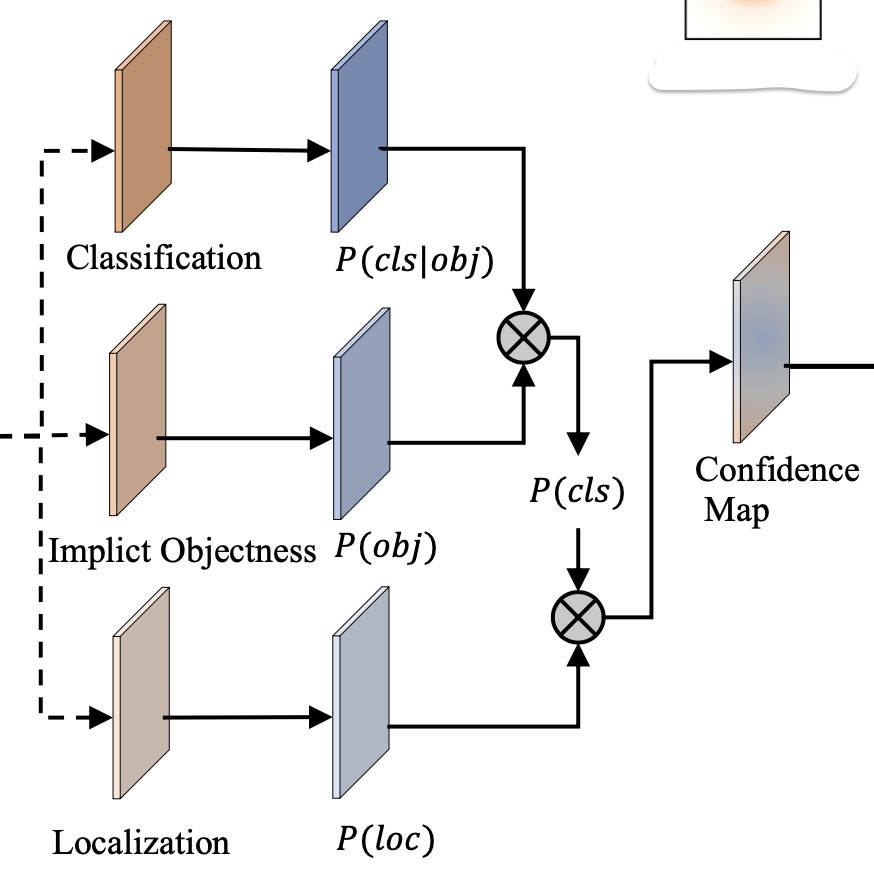
增加Implicit-Objectness分支,抑制false-pos(框内部分点不在物体上)
训练时分类分支一起训练
认为之前固定匹配模型的分类分支为已知点是正样本,预测点为某个类别的概率,即分类分支的结果为是
条件概率。
,
是参数
现在改为Impl-Obj分支预测,再和分类分支
一起得到
且增加localization conf作为计算样本权重的依据,通过指数函数将定位准确率转为likelihood,在计算loss体现。类似Learning From Noisy Anchors for One-Stage Object Detection 综合考虑分类和定位的性能
joint conf representation 经过指数计算,增强
(只会有一小部分落在物体上,得分高)
对一个GT框内的点计算权重,focus on proper loc inside bbox
融合,求正样本和负样本权重
,f normalize to [0,1],分数为sharpen权重分布
Loss函数
👆学习策略为一个box的训练,对一个box构建训练
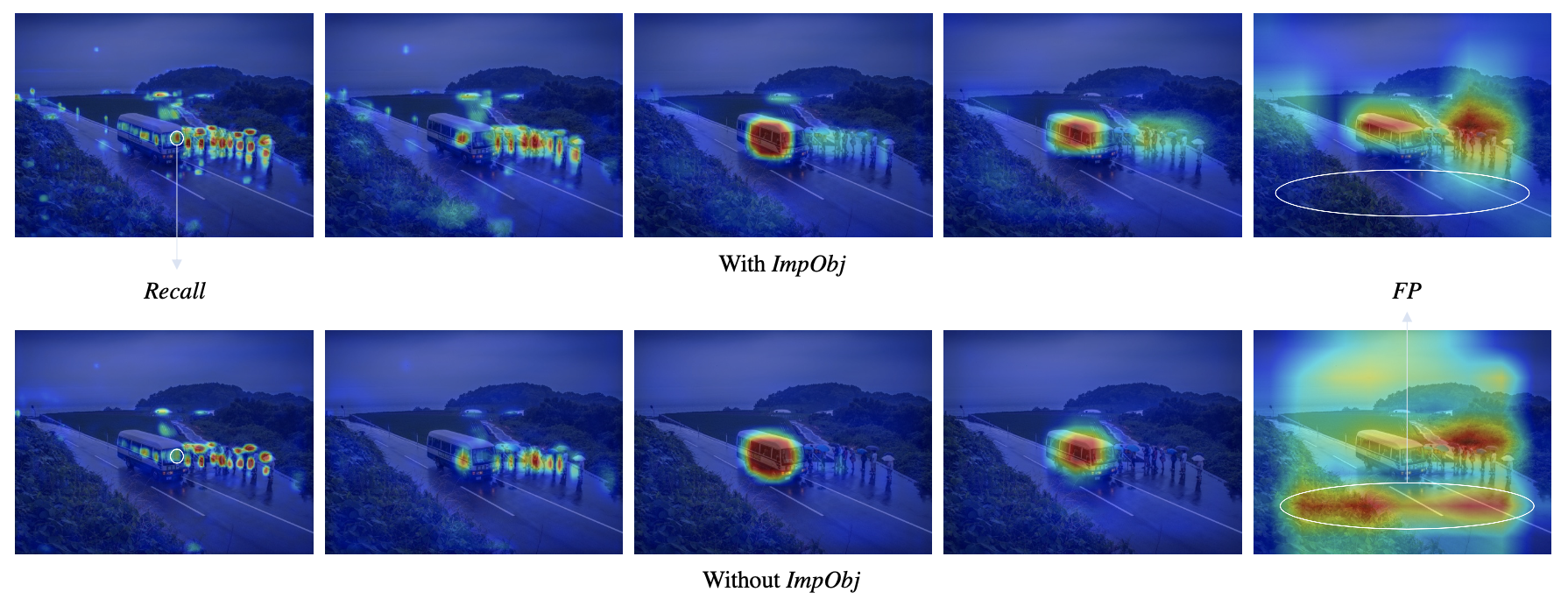
不同尺度热力图可视化👇

👇ImplicitObjectness抑制噪声效果显著
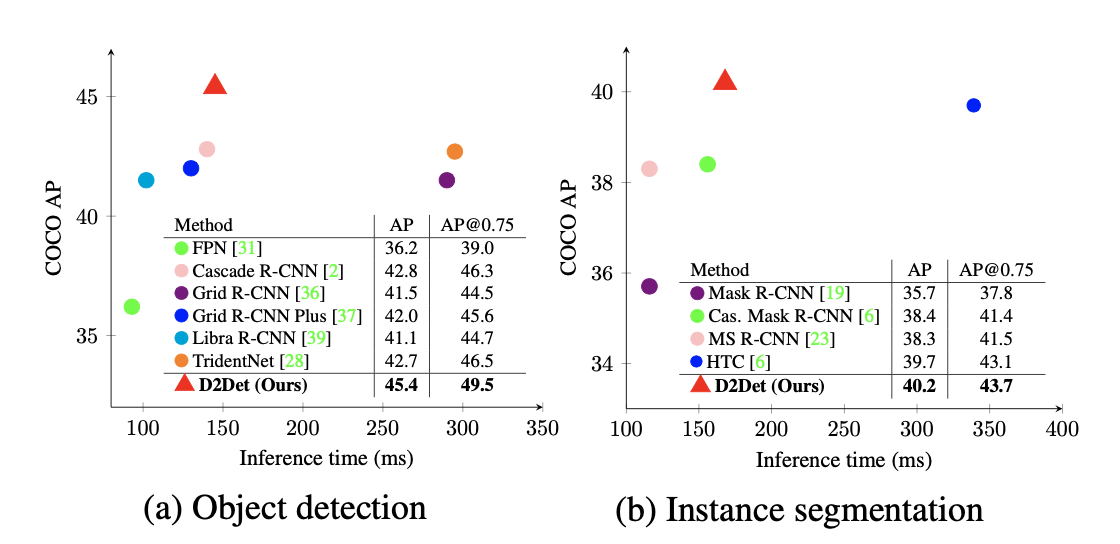
基于FCOS,提升2-3点,mAP=52.1%
Label-assignment
正负样本不均衡问题 It is observed that the classification metric could be very high for a trivial solution which predicts negative label for almost all candidate boxes, while the detection performance is poor
<img src="Figures/image-20200716164022633.png" alt="image-20200716164022633" style="zoom:50%;" />
负样本多,正样本分类结果对loss贡献少,对检测acc影响小
提出直接对AP(average precision)优化:AP Loss
把分类分支问题看为一个rank问题,计算AP Loss,采用error-driven方式优化
因为计算AP过程实际是对预测结果排序,再计算,所以把分类问题看作一个ranking问题:对于每一类,所有的正样本点排在负样本点之前(更高分)
AP-Loss的primary term为: . 其中
为两点的排序差距:
将分类预测的分数转化为排序x,作为损失函数的输入,H为Heaviside step function阶跃函数:
即只有j排在i之前时,才对有贡献。GT定义为
AP-Loss为:
(由于只有i j分属正负时
非0,同
的定义)
即为计算任意一个正样本P和一个负样本N的primary term。正样本之间没有,正负样本之间有损失
the update is directly derived from the difference between desired output and current output:
最小化AP-Loss到0,即最佳优化方向,y控制是否对于loss有贡献
优化时,衡量改变参数后x的变化与最佳优化方向之间的相似度,以及L2正则
,一阶泰勒展开算参数的优化方向
由于参数变化在BP过程中不变,所以最佳优化方向
即为x的梯度,链式求s的梯度
<img src="Figures/image-20200716173631622.png" alt="image-20200716173631622" style="zoom:50%;" />
性能基于RetinaNet提升3个点
基于AP-Loss,采用类似SVM方式对正负样本排序(margin)
增加对正负样本分布的改变 reweight
<img src="Figures/image-20200716173939029.png" alt="image-20200716173939029" style="zoom:50%;" />
采用3D卷积进行多尺度特征融合,不同层融合权重不同
特征金字塔不同层之间存在semantic gap,之前采用feature fusion解决但没有提取intrinsic property
Pyramid Conv PConv: 在尺度维上 (不同层特征图) 做卷积(like spatial conv),3D conv
选择三层,底层采用stride卷积,中间普通卷积,上层bilinear upsampling。控制不同层的不同stride来获得相同大小的输出,并相加。时间成本为1.5倍
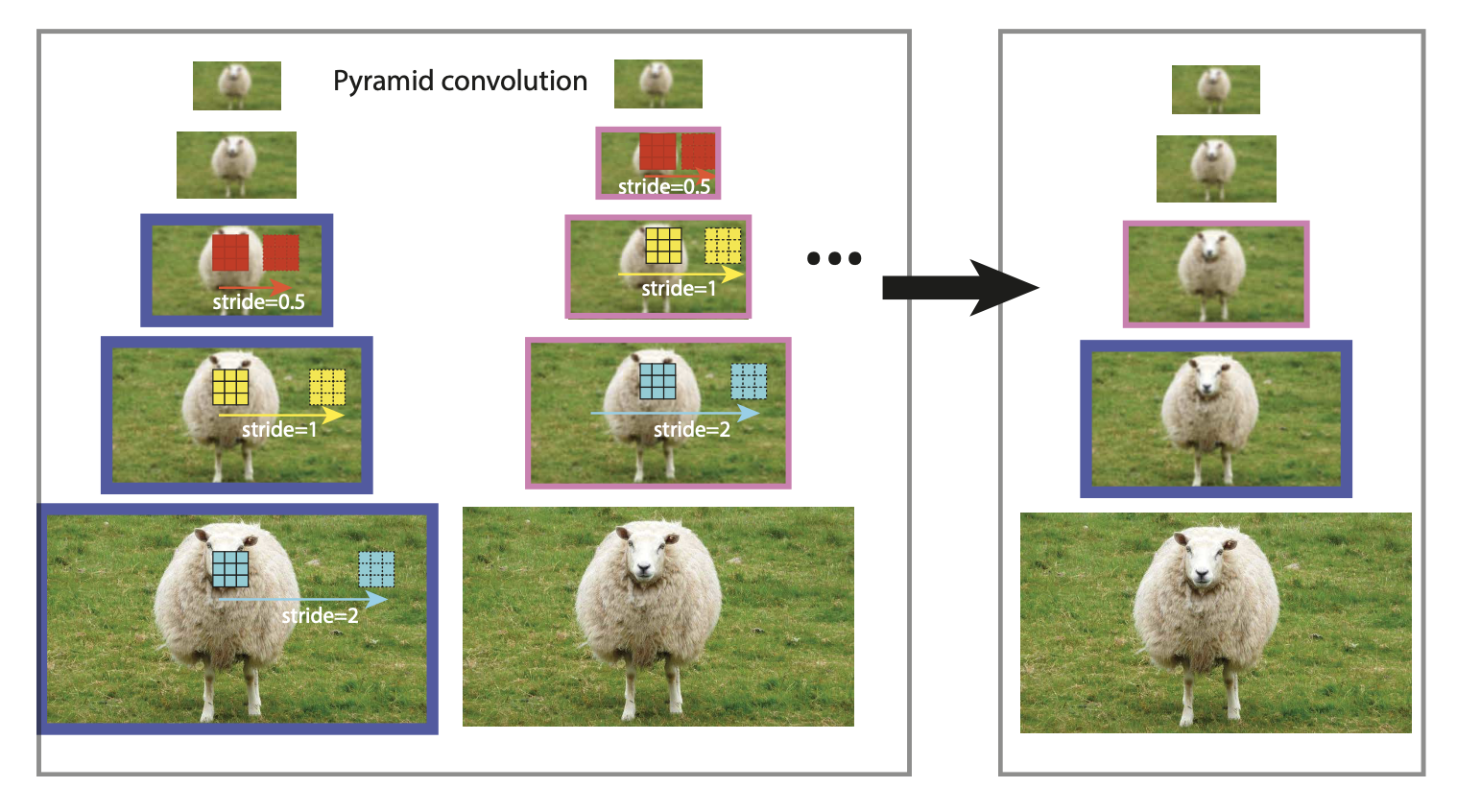
BN修改为整个特征金字塔层共享统计量,效果类似sync_bn,同步不同位置上的统计量,统计范围更广
BN = standardization(,
) + scale_shift(
,
),统计卷积的bn为每张特征图,即在channel维的统计(channel个统计量),统计不同样本在同一个channel上所有wh点的batch statistics
和
(reduce at batch dimension)。每张特征图一对parameters
和
(https://zhuanlan.zhihu.com/p/43200897)
可以证明PConv能够提取Gaussian Pyramid(不同高斯模糊核对图片处理) 尺度不变的特征,即如果原图物体尺度变化,则可通过对PConv提取的特征shift得到改变后物体的特征 论文中有证明
Scale-Equalizing Pyramid Conv SEPC: PConv的升级版,通过deformable conv实现对不同尺度特征的对齐。
def pconv_module_forward(x, conv2D_list):
# x: input feature list [p3,p4,p5,p6,p7] # conv2D_list: conv2D module list,
# [nn.Conv2D(stride=2),nn.Conv2D(),nn.Conv2D()]
out_x = []
for level in range(len(x)):
tmp = conv2D_list[1](x[level])
if level > 0:
tmp += conv2D_list[0](x[level-1])
if level < len(x) - 1:
tmp += Upsample(conv2D_list[2](x[level+1])
out_x.append(tmp)
return out_x
最底层普通卷积kernel size不变,其他层使用deformable conv

因为feature pyramid中由于backbone非线性操作,相对于gaussian pyramid特征不对齐,所以只通过dilation提取特征不全面,改用d-conv
SEPC is an improved version of pconv, to relax the discrepancy of feature pyramid from a Gaussian pyramid by aligning the feature map of higher layers with the lowest layer
底层特征采用普通卷积,卷积结果作为权重向上层的d-conv共享(卷积结果作为d-conv的一个输入求offset,类似CentripetalNet中)
SEPC模块用于取代RetinaNet的detection head的卷积模块
本质为一种pix-wise or fine-grained 的feature fusion,多尺度特征图通过卷积操作进行特征融合

性能提升明显
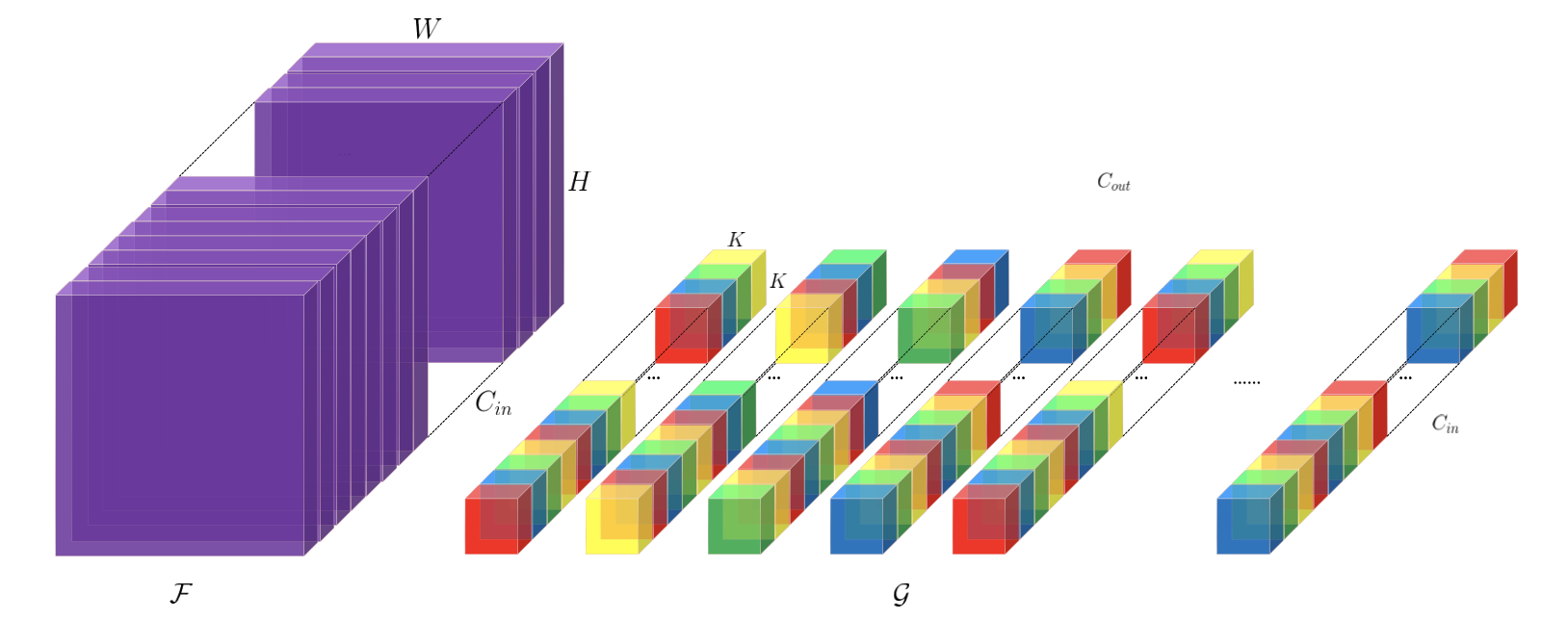
提取多尺度特征
一个卷积核不同通道不同dilation rate(不同颜色表示不同dilate)
扩张率在in通道上循环交替排布(👆T=4循环排列),在out通道维度上也循环排列
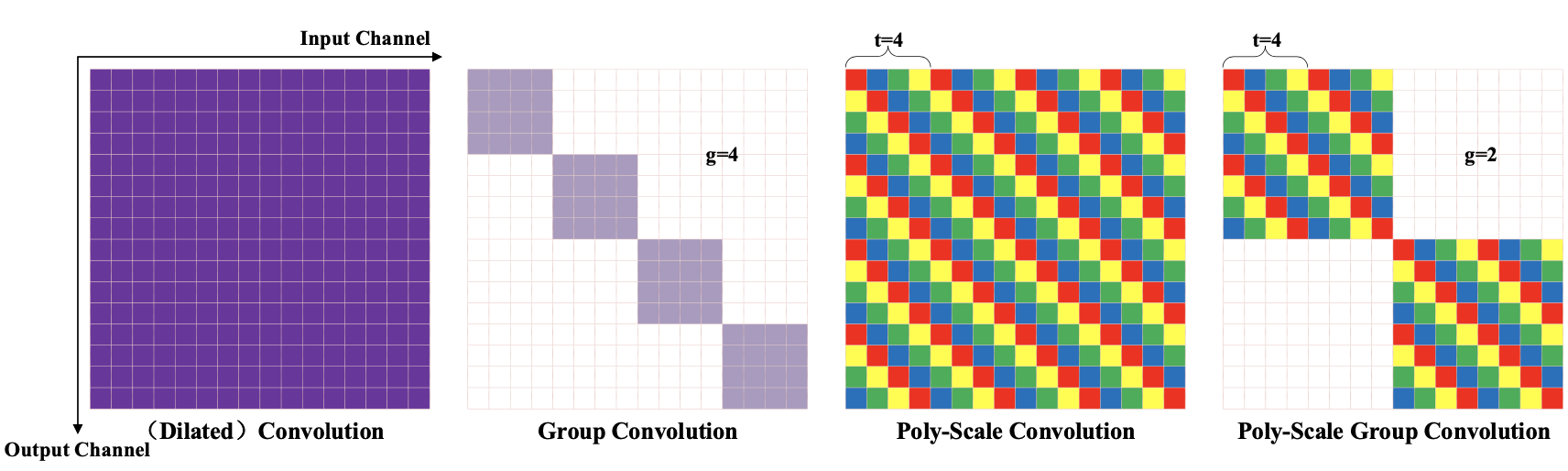
Fast RCNN替换backbone中所有卷积,FPN neck不变,提升2点左右
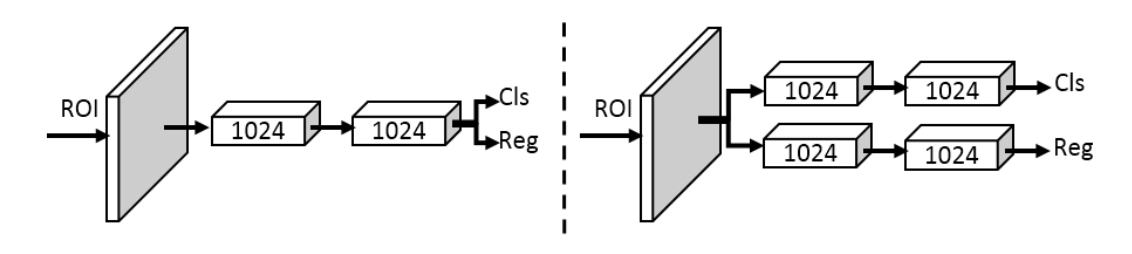
检测头进行双路分支改进
二阶段检测器中,对proposal处理的传统检测头采用conv层,或者fast rcnn使用fc层处理

fc层作为head,由于全连接操作不同位置权重不共享,对于位置更加敏感(小位置变化大的输出结果变化),适合分类
conv层作为head,由于卷积操作不同位置权重共享,适合回归整个物体(coco2018结果表明可以使用conv层作为bbox的预测头)
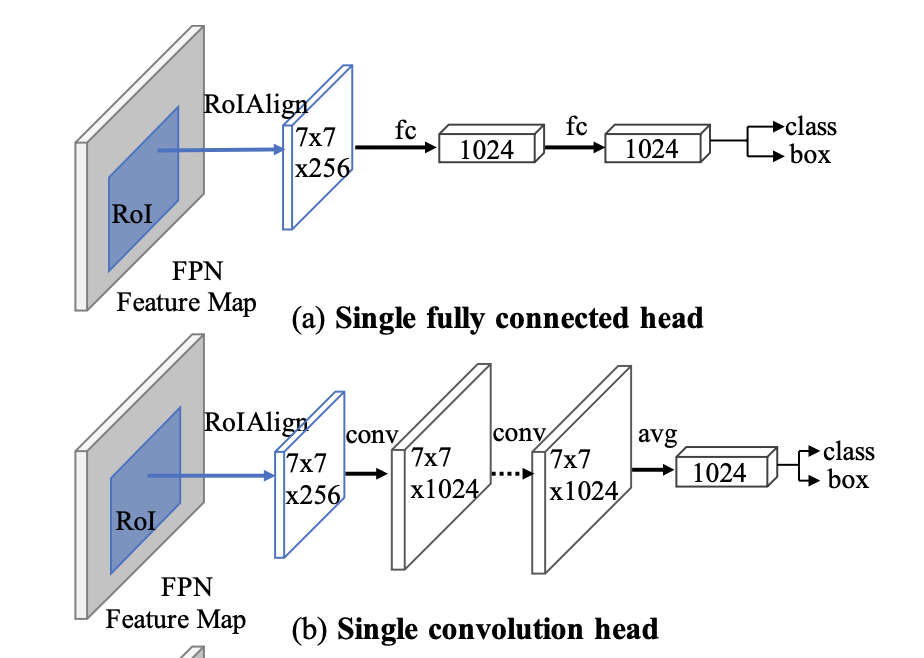
分析conv作为head的分类回归结果👇

fc作为head的分类回归结果👆
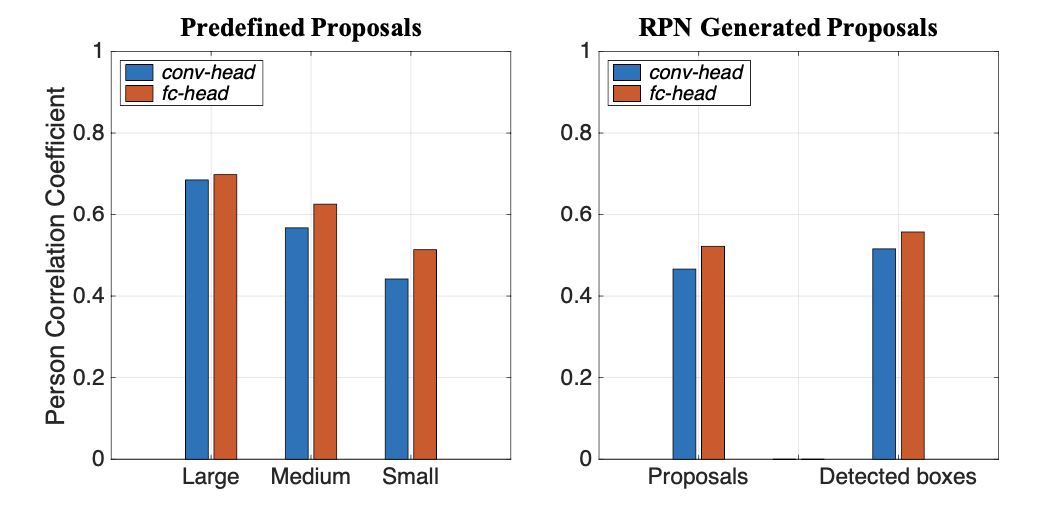
可视化关联关系:conv-head采用得到的特征图cos距离,7x7grid,每个点产生7x7大小的和其他任意点的关联矩阵;fc-head对fc层权重变换输出7x7特征图
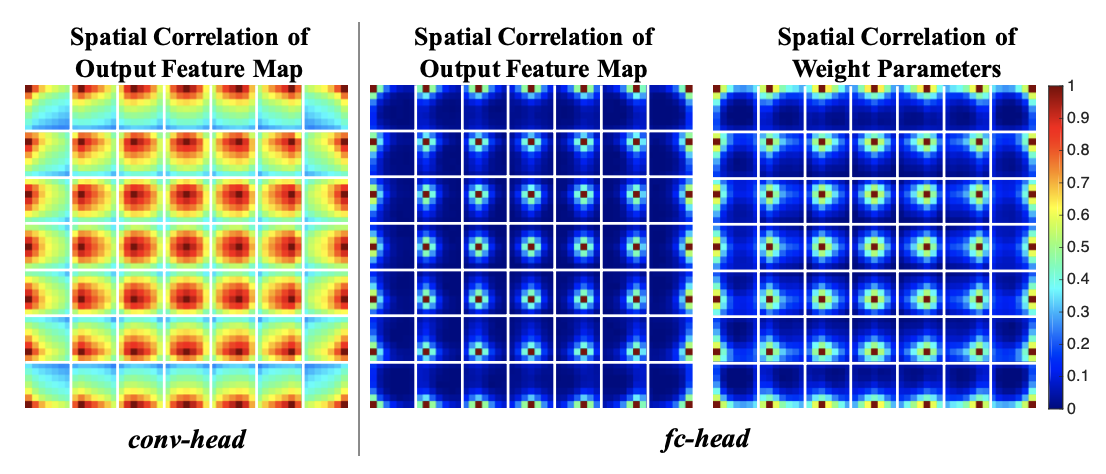
conv-head计算的点和周围关联关系大
两个分支,conv-head用于回归,fc-head用于分类
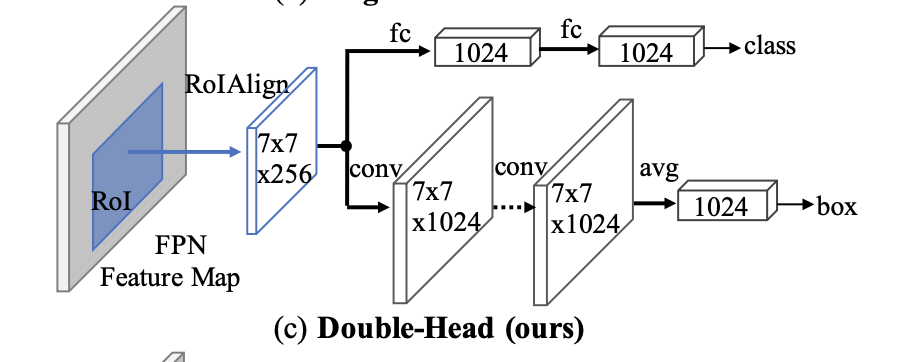
改进:extend,训练时利用conv-head的分类损失和fc-head的回归损失进行监督(unfocused task supervision)
,
同时对分类分数进行二分支融合(classifiers are complimentary)
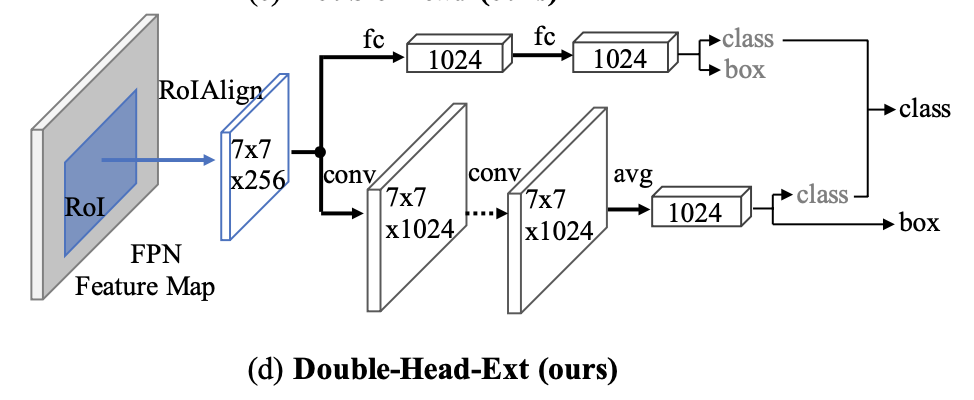
FPN+2.5~3.8 val AP
一阶段回归分支操作移植到二阶段
deformable pooling + weighted pooling
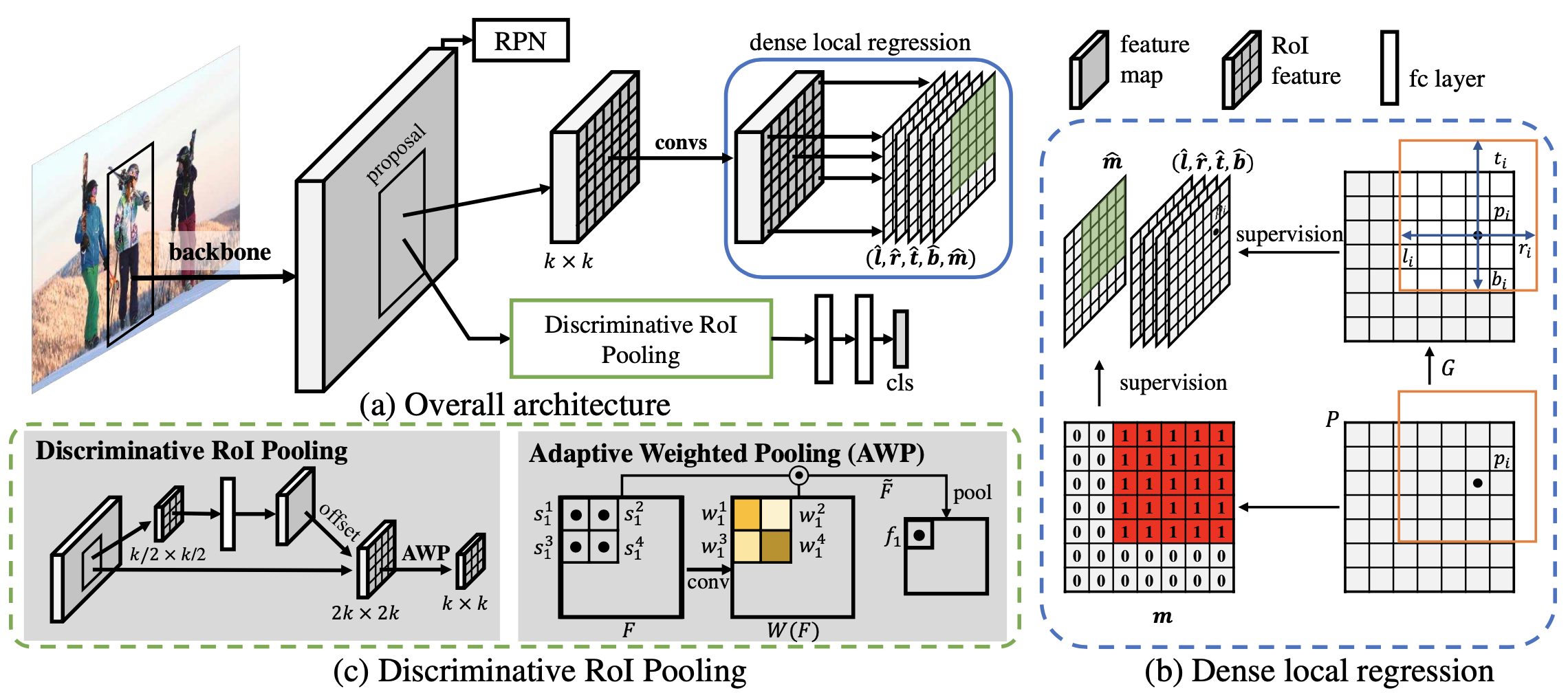
把RoI看作类似一阶段中的特征图。之前二阶段检测器对于一个RoI只预测一个框 (FC+预测),改成RoI中每个点都预测一个框(dense prediction)。预测中间点到box上下左右的距离 (FCOS)
增加binary overlap prediction (),对RoI和GT重叠部分为1,只有为1的点的预测结果有效。
类似一阶段中每点预测bbox,预测IoU/objectness
deformable pooling + weighted pooling
pooling的weighted权重通过输入特征操作得到(类似self-attention)👇W为计算的权重
 性能提升较明显: multi-scale 50.1
性能提升较明显: multi-scale 50.1
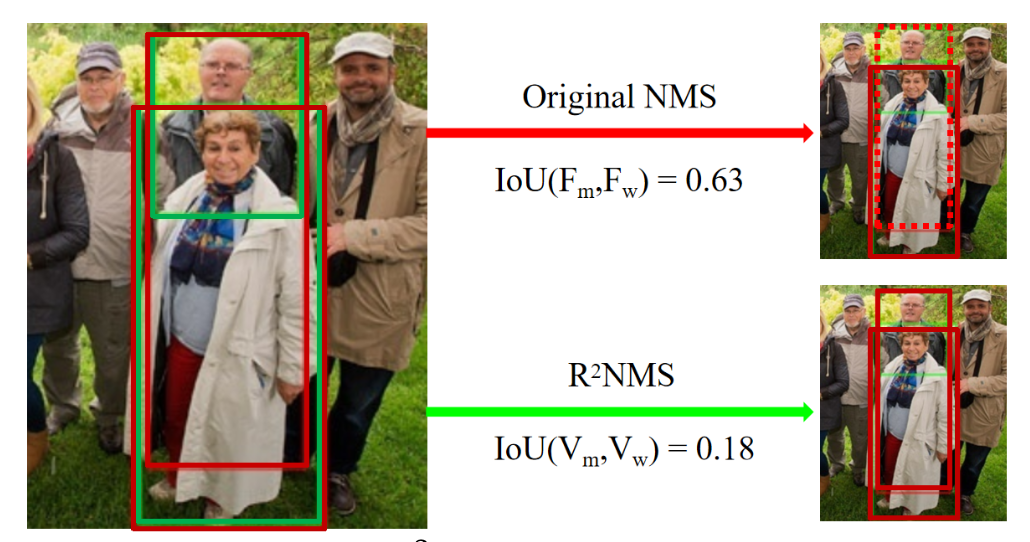
基于bi-box regre. 根据vis框进行NMS
行人检测中重叠,类内重叠Replusion Loss和AggLoss惩罚两个人中间的box,但是box的重叠仍然会导致在NMS过程中被误删
Adaptive NMS中GT-density和Pred-density的inconsistency
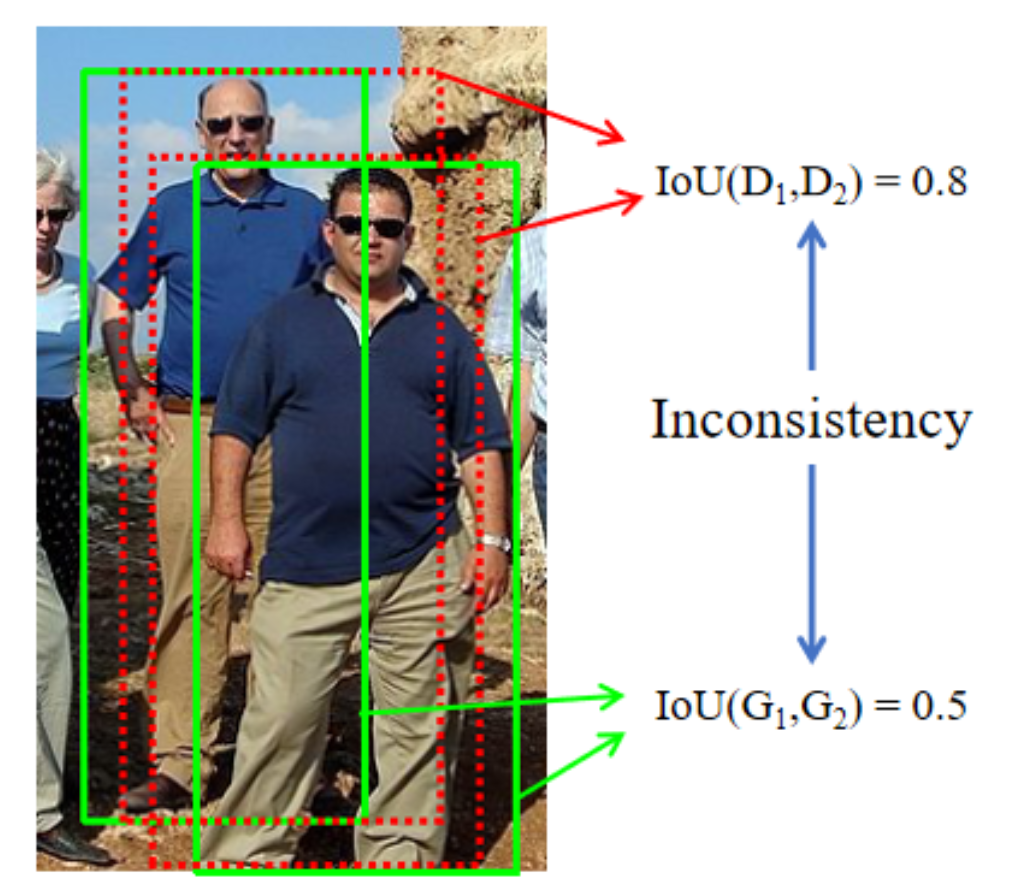
GT框不密集,但Pred-box是密集的。Adaptive NMS预测GT的密集程度,而NMS和Pred的密集程度有关。👆预测绿框不密集,所以红框不会被保留
通过计算visible部分的IoU而不是full部分的IoU进行NMS
重叠不同物体的检测框full-IoU大,vis-IoU小。重叠同一物体full-IoU和vis-IoU都大 vis-IoU判别
Paired RPN + Paired Proposal Feature Extractor + Pair RCNN
GT标注为pair Q=(F,V),全身框和可见框
从一个anchor回归出full和visible的proposal(为了inherent correspondence)
anchor和一对GT标注的匹配标准:
and
full和vis的回归训练策略同bi-box regression
融合full/vis两个proposal的特征
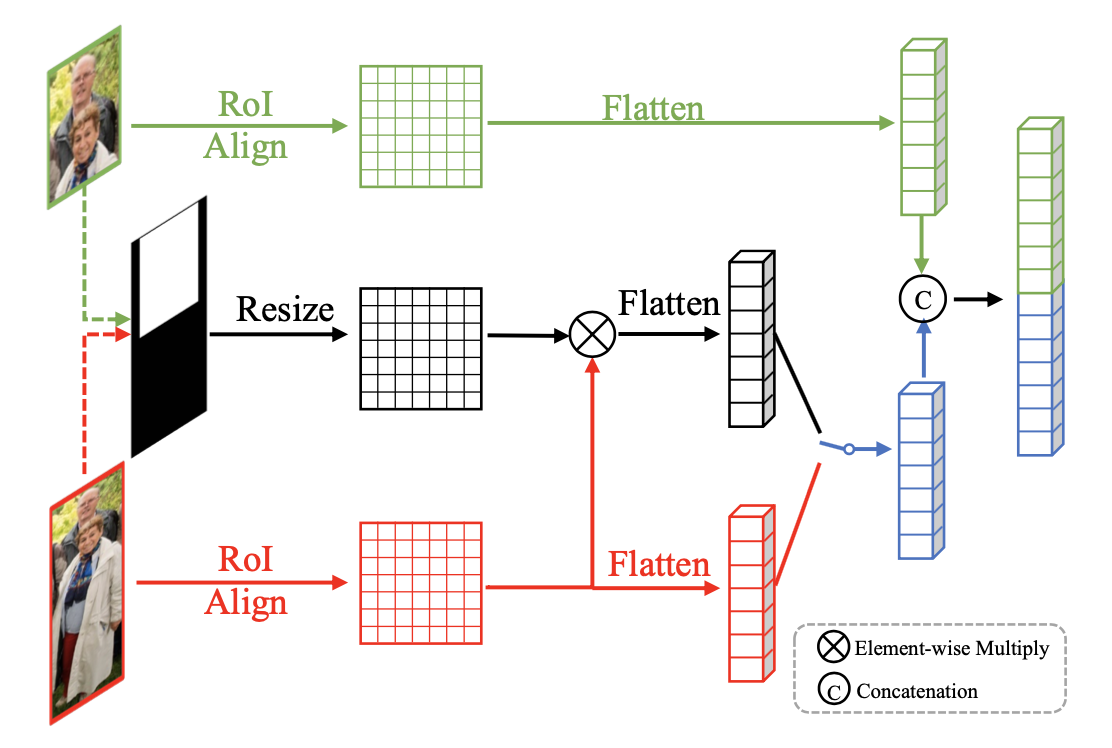
<font color="#00dd00">绿色分支</font>+<font color="dd0000">红色分支</font>:简单的concat两个proposal的特征向量
<font color="00dd00">绿色分支</font>+黑色分支:visible region attention/mask,构建visible部分的0/1 mask,与full特征点乘得
,再concat
和
融合特征和proposal作为输入,两个分支分别预测full和vis的检测框
proposal和一对GT的匹配标准:
and
性能提升明显
NAS整体搜索,基于FBNet
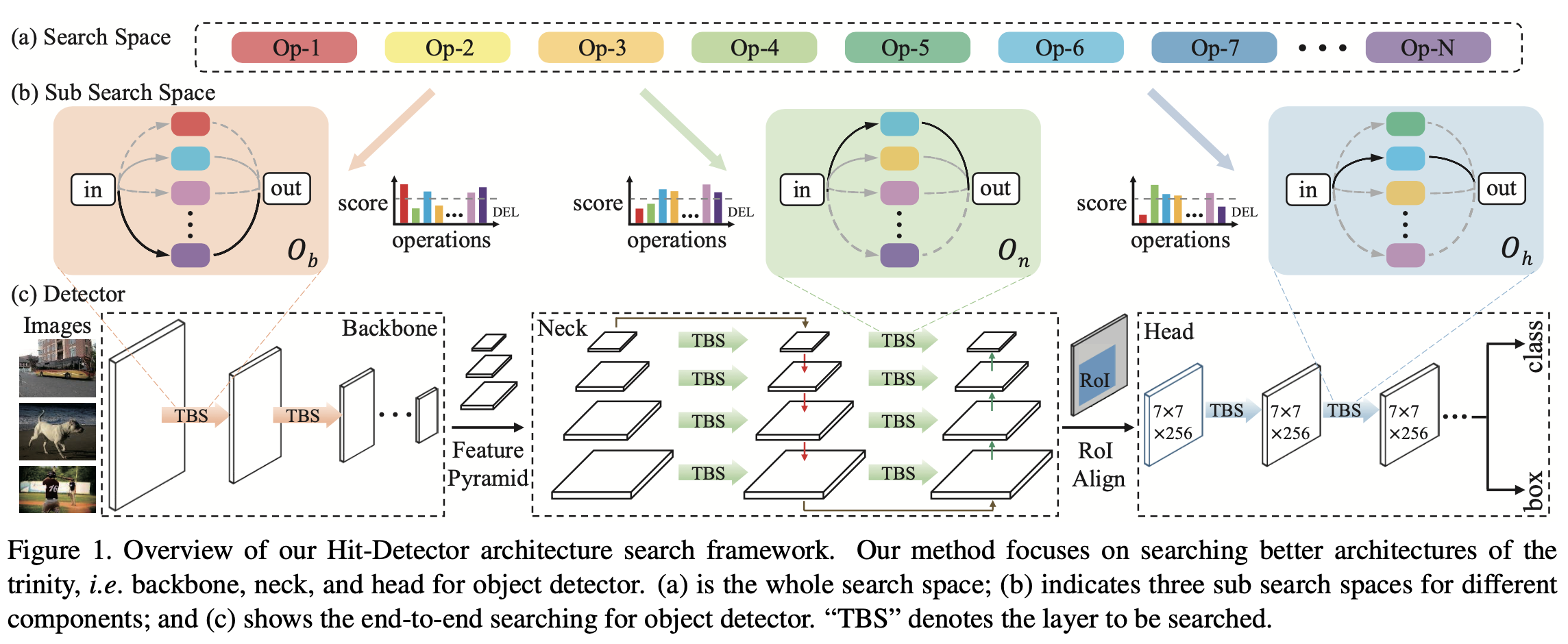
二阶段检测器:backbone + neck(feature pyramid & fusing) + RPN(fixed) + Head
NATS和DetNAS搜索backbone,NAS-FPN搜FPN,Auto-FPN搜fusing和Head
单独搜索效果较差,采用整体每个部件(backbone: , neck:
, head:
)一起搜索,end-to-end search
每个component采用逐层搜索,构建每个操作用在每一层的得分矩阵,选择概率
对一个操作用在不同层的得分进行L2正则化(column-space regularization),减少得分的数值大小:
选择最大max的一个操作,但为了可微采用softmax来选择(continuous relaxation)
搜索backbone时搜索空间的节点计算(differentiable):
搜索neck时搜lateral connection,搜索Head时搜fc预测前的block
优化时增加FLOPS约束:
首先固定在一半的数据上训练求
更新
,再固定
在剩下的数据上训练求
更新架构
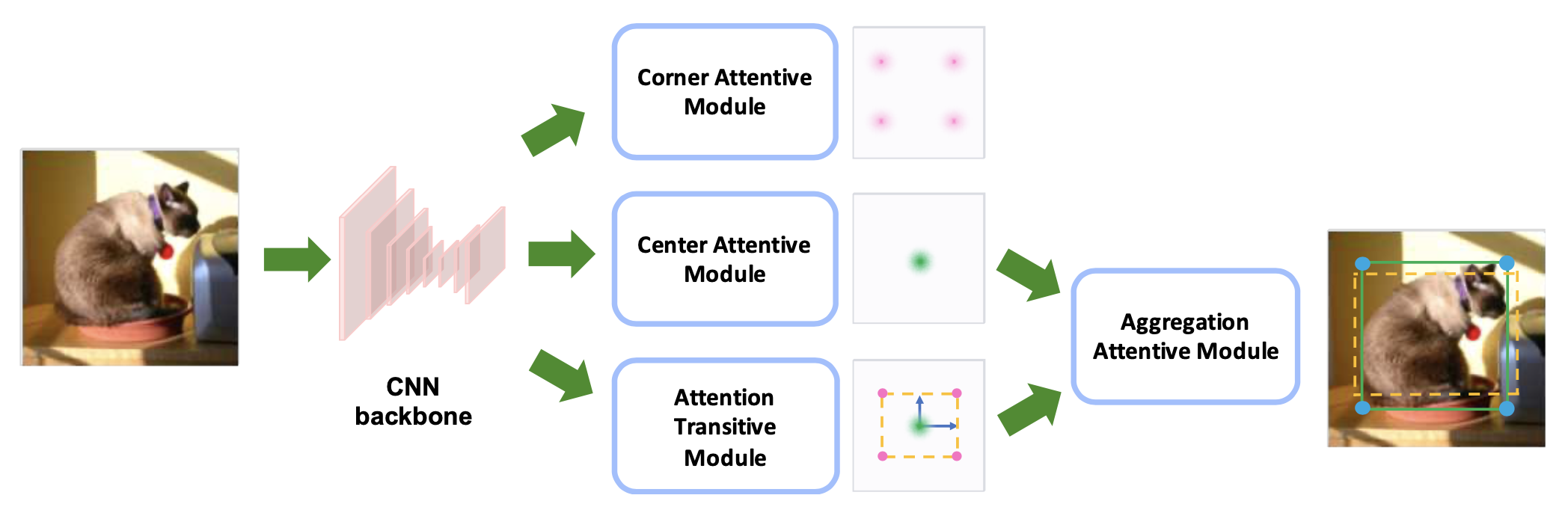
Center Attentive Module产生中心点和类别;Attention Transitive Module产生wh;Aggregation Attentive Module融合两分支的特征(双线性插值)和预测,并对预测框进行refine;Corner Attentive Module只有一个block产生角点预测,用于backbone监督信号,测试时去掉。
相比CenterNet改进:1. 通过Aggregation进行二步refine 2. 增加corner分支的监督信号有助于对边缘的检测(帮助预测wh的分支) 3. L1作为box训练损失

👆test-dev上性能,速度提升明显,快于yolov3
loss函数增加权重,选择回归分类分数高的框增大其loss贡献
对loss学习时的修改
之前的检测器评价anchor好坏使用IoU,harsh的划分导致噪声和不易训练
<img src="Figures/image-20200711120826876.png" alt="image-20200711120826876" style="zoom:30%;" />
拖车:IoU大但包含其他物体;长颈鹿:包含关键特征但IoU小
以IoU作为正负样本划分会导致噪声,需要根据回归分类结果(cleanliness)划分
分类上采用对cleanliness的预测代替之前根据IoU的pos/neg的0/1预测,RPN的soft-label,类似IoU-Net的预测IoU/soft-objectness
对按IoU划分的中部分较高IoU的anchor计算cleanliness,即回归分类的性能
稳定训练,前几个iter采用anchor-gt的IoU而不是预测结果的IoU计算c
,用于RPN或objectness预测
定位上采用根据c对中anchor计算reweight r,对anchor回归损失加权。
为box和匹配到的GT的IoU(匹配用最大IoU方法)
,其中
,为增大variance,并将
均值正则化到1
<img src="Figures/image-20200711123828365.png" alt="image-20200711123828365" style="zoom:50%;" />
使用卷积层截断梯度,减少直接相连,防止梯度重复计算
densenet中不断的concat会让梯度反传时后面的梯度不断传到前面,计算量大,重复计算
反传
例如在最后一层计算过程中,由于和前面层直接连接,梯度会一直回传到w1
提出:Partial Dense Block 输入特征channel上分为两部分,一部分直接相连,另外部分dense block。Partial Transition Layer 融合时采用transition层截断梯度的传播

的梯度只传递到
,之后梯度全部从
开始传
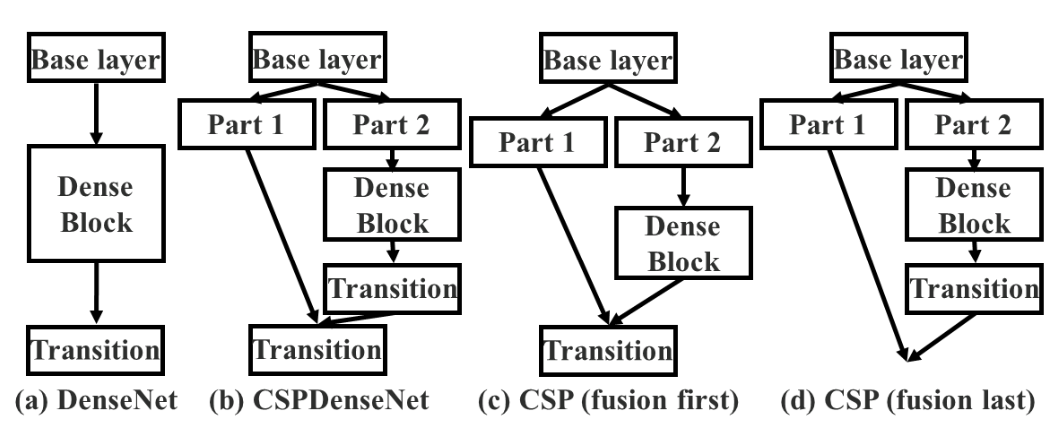
Fusion first能截断更多梯度传递(如后续部分到part1的梯度),但性能较差;采用fusion last
提出EFM,临近层特征融合,防止distract
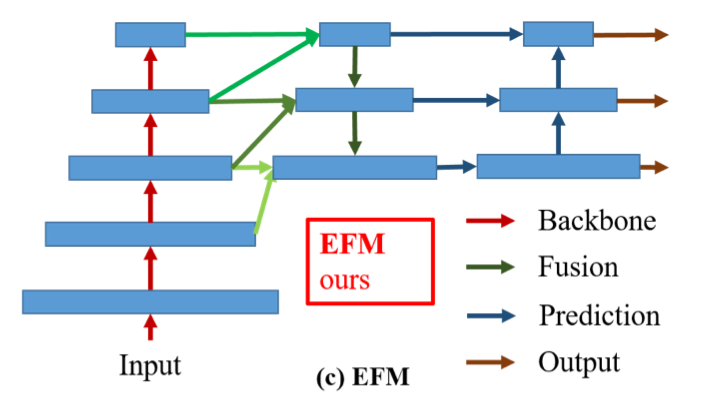
检测任务性能提升明显
采用transformer/self-attention方式进行多尺度特征融合/交互
Non-local只对同一尺度的不同空间特征交互,改进space+scale
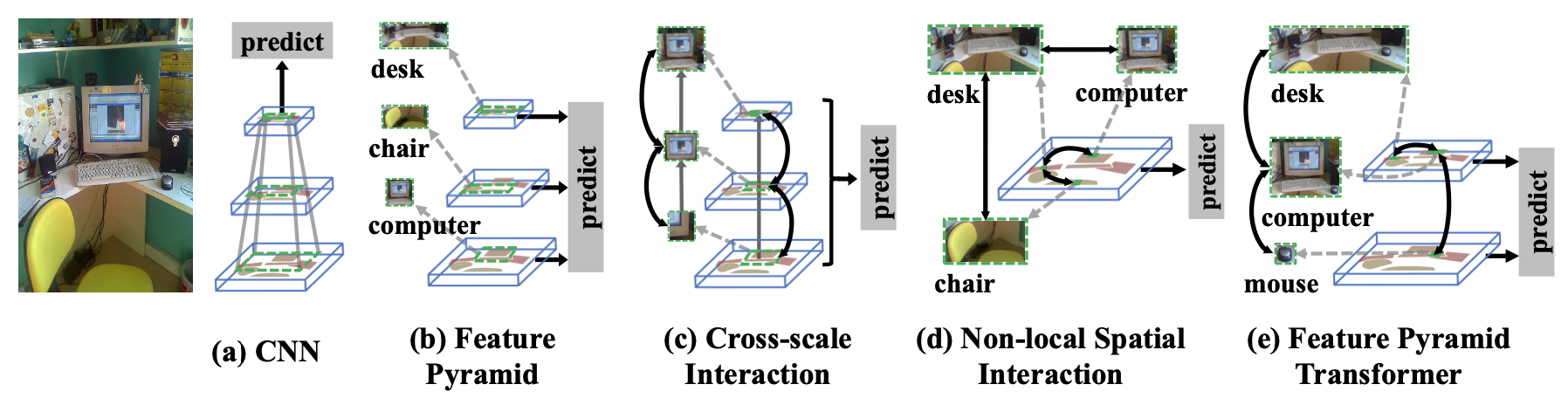
不同层的不同空间位置的物体interaction(co-occurring in multiple scales)
用于一张特征图不同位置特征。看作self-attention,输入表示
位置经过
提取后的query,
为key,
为
位置的value
先dot product计算i-query和j-key相似度,softmax标准化得到权重,和j-value相乘的到结果
用于一张图上co-occurring物体特征。把query和key分成份,每部分计算相似度
,使用Mixture of Softmax作为标准化函数(加权求和
)
<img src="Figures/image-20200818145143482.png" alt="image-20200818145143482" style="zoom:50%;" />
top-down融合,ground高层concept特征到低层pixel特征,高层低层
采用负欧式距离计算不同层之间特征相似度
表示
层
位置的特征,
表示
层
位置,计算的到
分割任务需要局部信息,传统采用直接相加,而用GT会带来全局信息,提出Locality-constrained Grounding Transformer,只和一部分
交互
<img src="Figures/image-20200818145429855.png" alt="image-20200818145429855" style="zoom:50%;" />
bottom-up, rendering high-level concept with low-level pixels
低层的和
,高层为
首先GAP计算为权重
,权重
再和
相乘refine,最后和downsample (conv+stride)的
相加
resnet,faster rcnn head
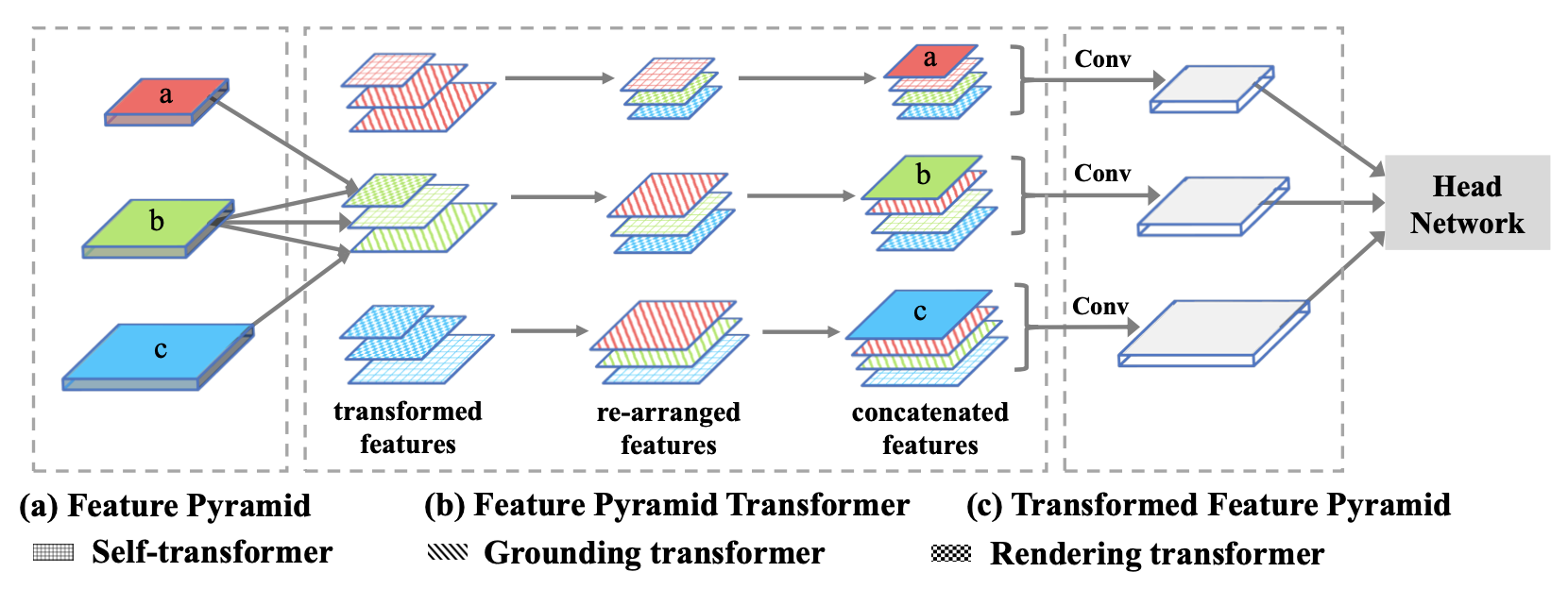
高层计算用于GT的特征,低层计算用于RT的特征,transformer融合的到新特征,concat
参数量,计算量增加大
explicit border information
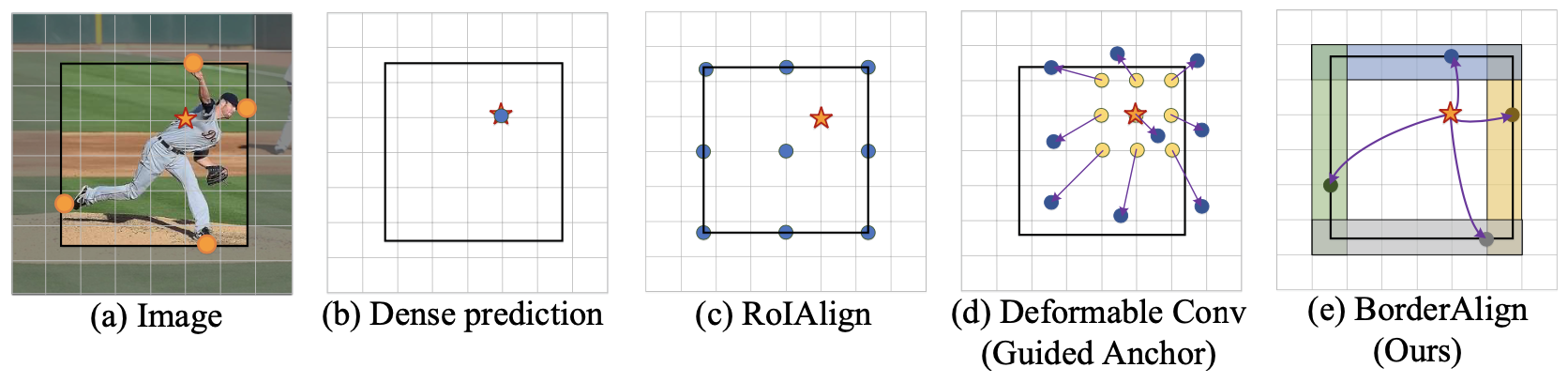
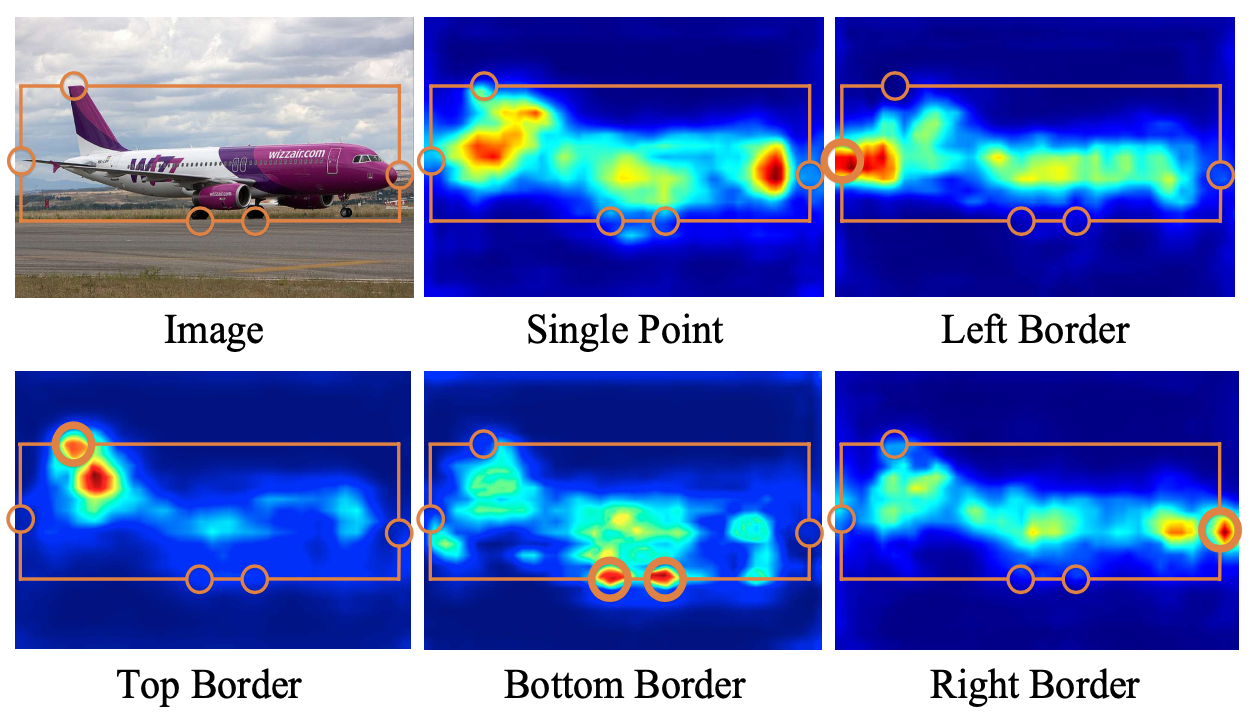
borderdet增强了边缘的特征
原始特征通道数为C,构建5C通道的特征,表示上下左右特征和原始点的特征。输入coarse box reg的bbox。
对于每个ij点,4C分别选择其对应预测框的边上响应最大的特征作为这个点的输出特征(+原始特征=5C x W x H特征图)
的coarse预测结果为
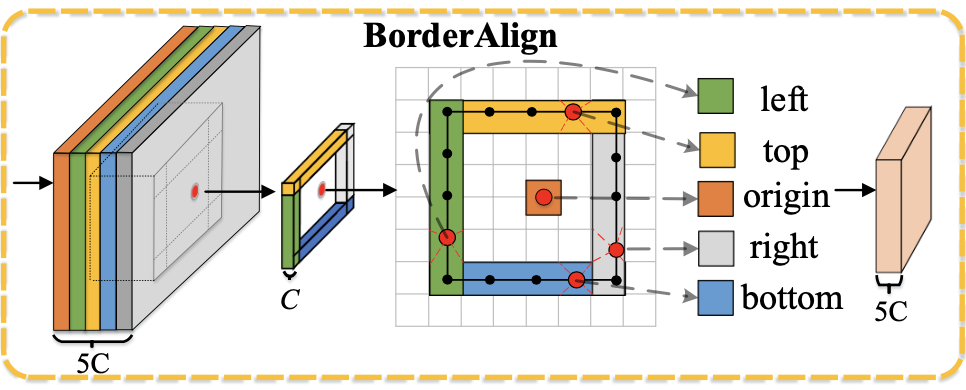
Border Alignment Module对特征升维,BorderAlign,降维👇
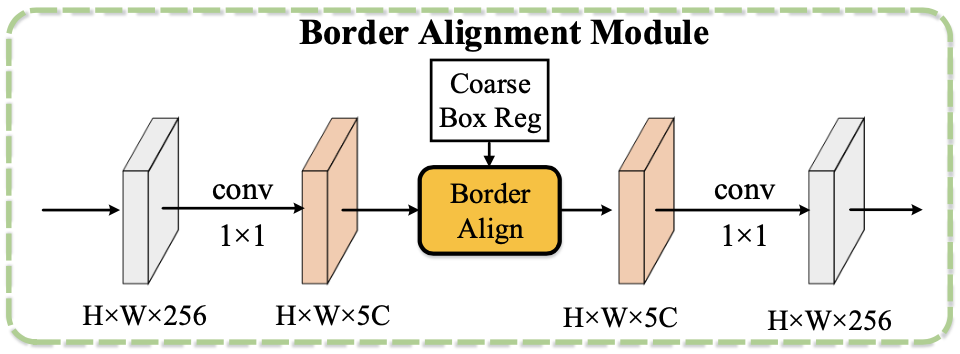
BorderDet分别在定位和分类分支使用BAM,BAM使用定位分支的第一步的定位结果,再去refine,组合成为最后输出👇
<img src="Figures/image-20200819231428705.png" alt="image-20200819231428705" style="zoom:50%;" />
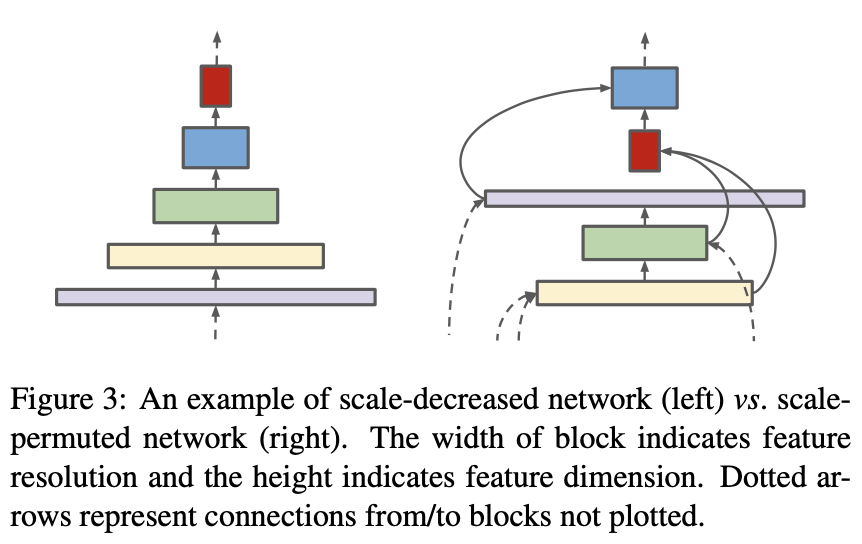
NAS+检测,encoder+decoder结构不好 (scale decreased model)
尺度增大减小,不同尺度特征连接
提出scale-permuted model,保证:1. 特征图尺度可以随时增大减小 2. 不同尺度的特征可以连接进行融合
直接搜索整个网络,而不是分别搜索backbone和fpn
逐步替换resnet👇,红色为输出层,可以看作backbone+FPN
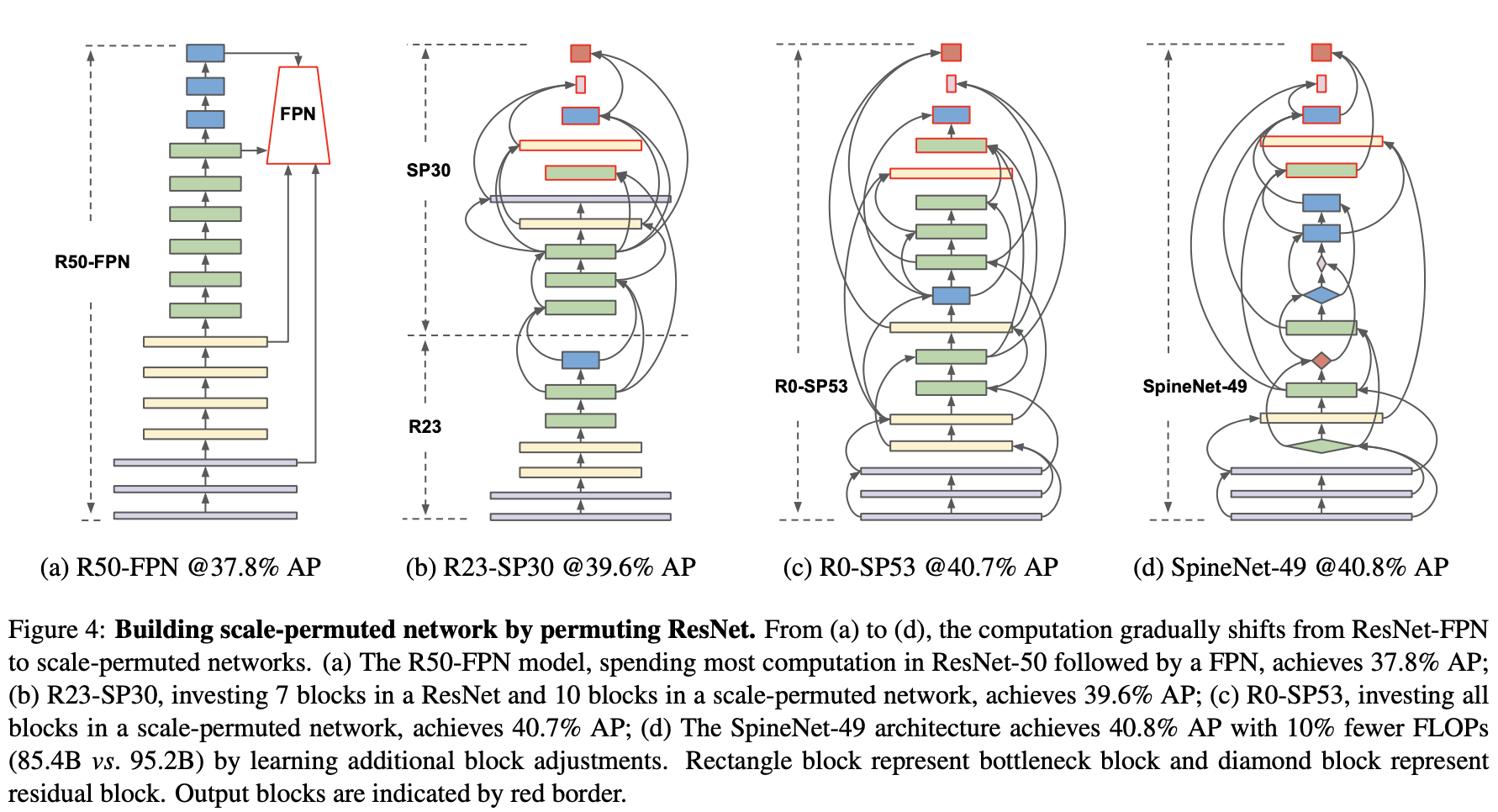
Multi-scale, DropBlock, stochastic depth, swish activation
性能提升明显 mAP=52.1
FPN top-down和botton-up两次都预测监督算loss
拆分cls和reg head
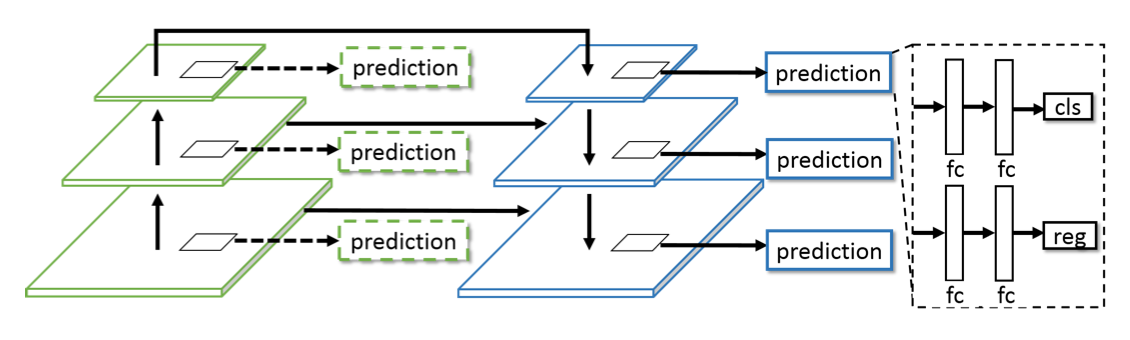
一个卷积拆分为多个不同receptive field的分组卷积
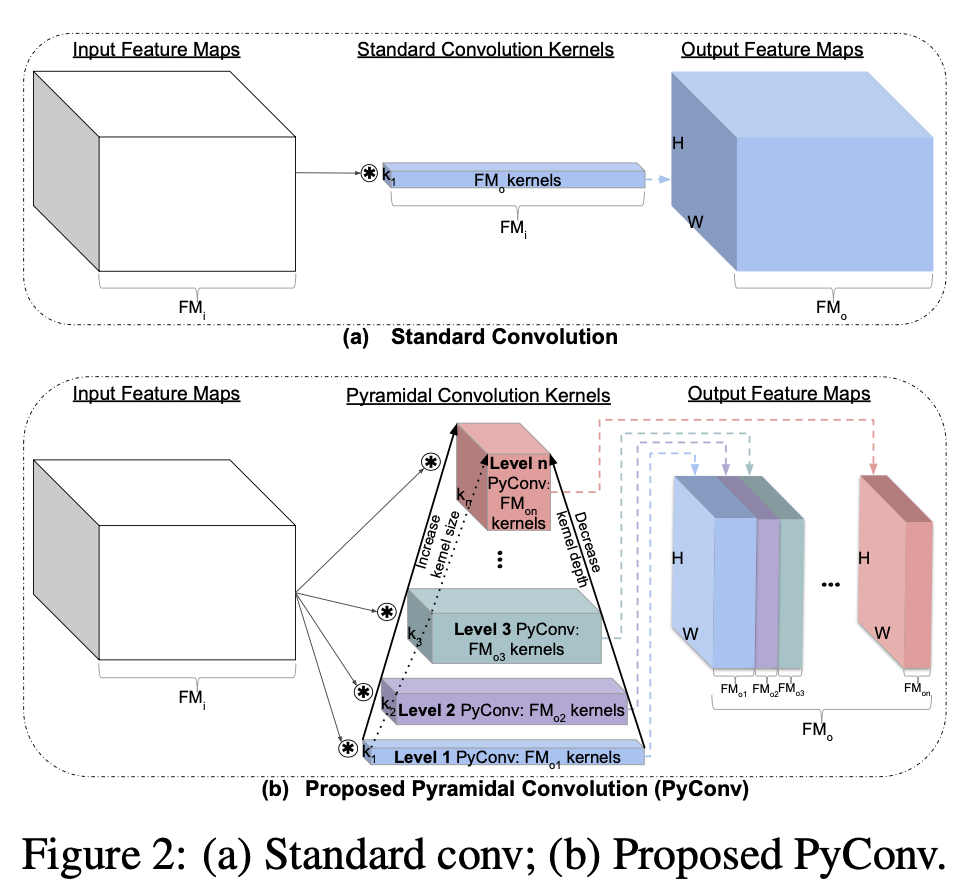
Bottom-up: 感受野逐渐增大,kernel深度逐渐减小
kernel depth (输出通道数):
对SSD模型有提升
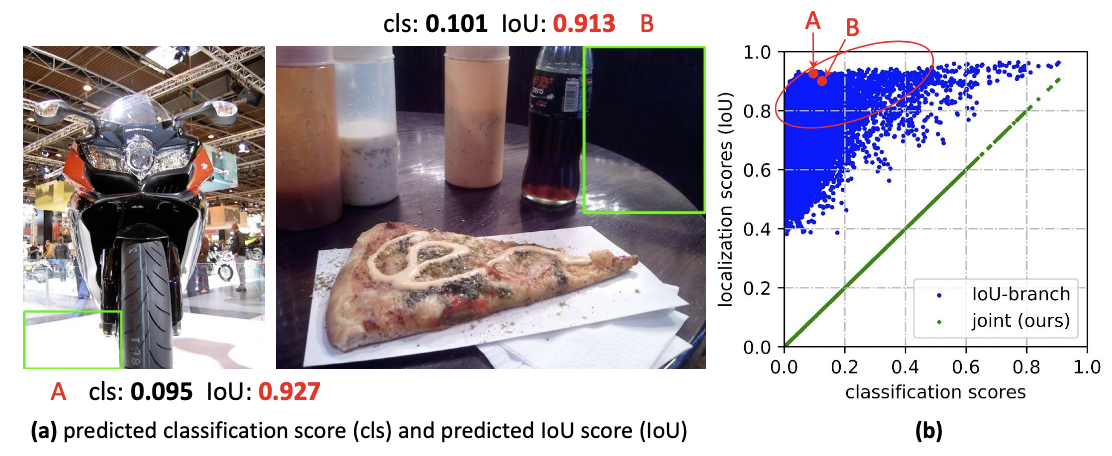
👆IoU(quality)和cls-score不match,👇独立预测
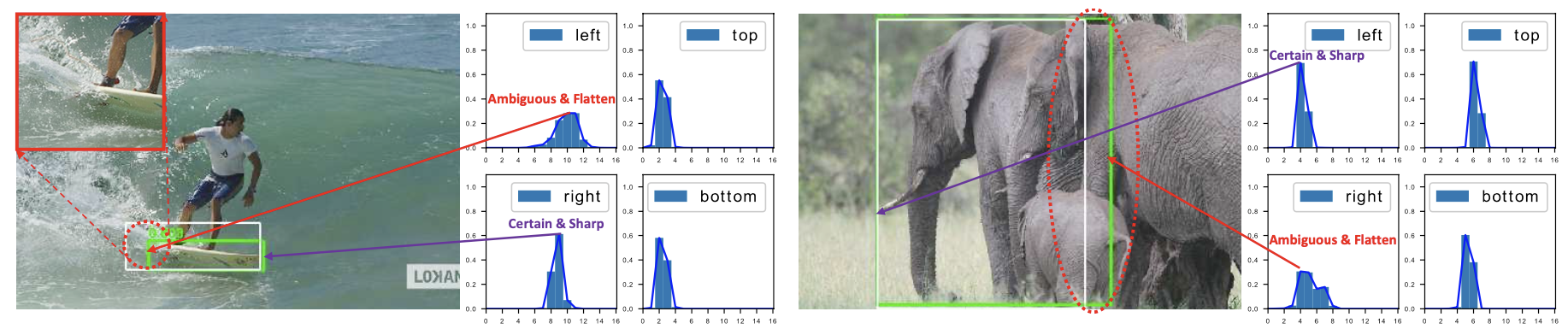
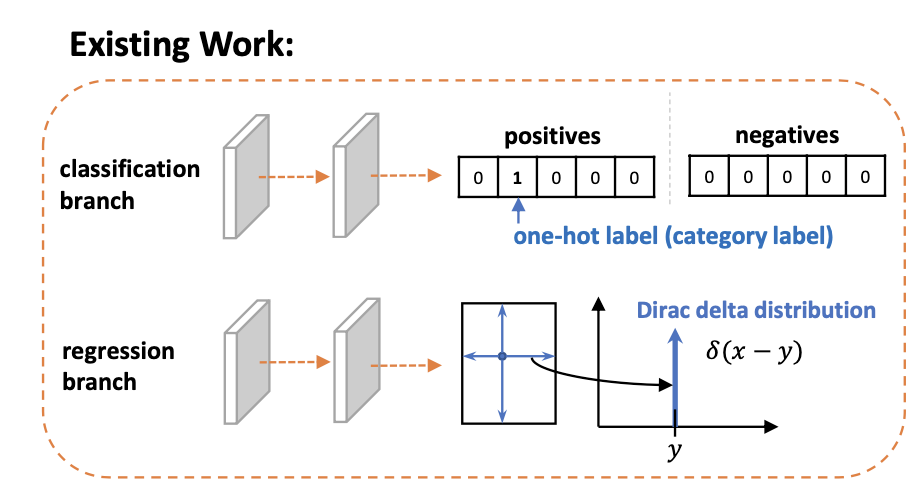
👆传统为冲击函数(Dirac delta dist.),无法建模不确定性
提出预测分类-质量联合表示(smooth label),离散label,将Focal Loss的优化改 「展开pos+neg」
👆之前是冲击函数,只有标注y出概率最大,其他为0,对于不确定的边界没有监督
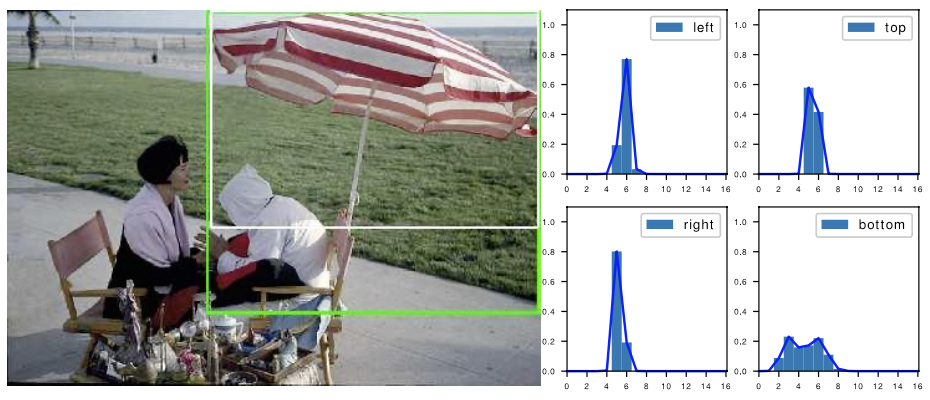
👆不确定边界 bottom,双峰
<img src="Figures/image-20200906110316101.png" alt="image-20200906110316101" style="zoom:50%;" />
传统 ,冲击函数,只预测一点
提出通过分布预测label
分布的积分
从冲击函数,到先验高斯分布,到任意分布,建模随机性
<img src="Figures/image-20200906110336213.png" alt="image-20200906110336213" style="zoom:50%;" />
离散化 ,
减少计算量,真实分布与标注位置距离不会太远,只计算左右最近两个
最后预测为左右最近两个位置的线性组合
QFL和DFL的统一表示 Generalized Focal Loss
训练损失
对所有位置计算QFL,对正样本
计算GIoU loss和DFL
DFL和IoU-loss优化bbox回归,分别建模uncertainty和IoU最大;QFL优化分类分支
对大目标提升效果好,+1 mAP
Ref: https://zhuanlan.zhihu.com/p/147691786